《Deep Learning with Python》by François Chollet
Even given the progress made so far, most of the fundamental questions in AI remain unanswered.

不知不覺兵役已經服完一半了,在軍中讀書的計畫也已來到第六本。今天要介紹的是 François Chollet 的 《Deep Learning with Python》,會挑這本是因為之前選的讀物除了 TechBridge 以外都是非技術類書籍(TechBridge 本身其實也只能歸類為單篇彙集),有好一段時間沒有讀這種系統性介紹特定技術的書籍,想換換口味。另一方面是我自己對神經網路本來就有些興趣,只是之前東摸一點西摸一點,對它的暸解還不是很多,剛好聽說這本書寫得簡單易懂,觀念上的解釋又鞭辟入裡,決定來一睹其風采。唯一的缺點大概就是在軍中沒有電腦可以讓我實驗書中的程式碼吧(嘆。
對於內容牽涉到比較多技術思維的書籍,我通常傾向做稍微詳細一點的筆記,所以這篇其實算是一份讀書筆記兼分章摘要。整體上來說我覺得這書寫的有趣又實用,對我啟發不小,誠心推薦給任何想踏進神經網路領域的新手,或是覺得有些觀念仍未弄清的老手看。至少我看完後心情還蠻亢奮的,決定之後再找時間來仔細讀讀 Ian Goodfellow 的聖經《Deep Learning》,應該也會收穫不少。
(本文圖片來源除 GAN 的示意圖取自机器之心外,其餘皆取自《Deep Learning with Python》by François Chollet 書中)
Ch1 What is Deep Learning
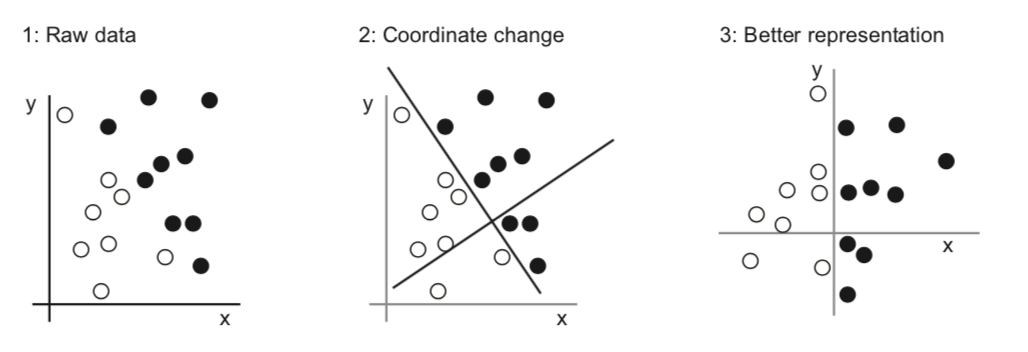
這章介紹了人工智慧(AI)、機器學習(Machine Learning)、深度學習(Deep Learning)彼此間的關係。簡單來說,機器學習是人工智慧的一種,而深度學習是機器學習的一種。機器學習和普通的人工智慧程式差別在於,普通程式是接受資料和規則算出答案,機器學習則是接受資料和答案來算出規則。大部分機器學習模型所追尋的「規則」,形式為「將資料轉換成一個有用的表示方式(representation),再透過這個表示方式得到答案」;而所謂的「學習」,一般是指「讓電腦自動從假設空間(Hypothesis Space )中搜索出最好的表示方式」這個行為。
舉例來說,平面上有一堆點,有些是圈有些是叉,我希望我的機器學習模型能透過點的座標自動分辨出哪些點是圈、哪些點是叉。此時我可以把我的假設空間(Hypothesis Space )設定為「空間中的任意直線」,然後試圖去找一條能完整的將圈和叉分開來的最佳直線。倘若這條直線找到了,那麼任選一點,該點「位在這個直線的哪一側」就是一個「有用的表示方式」,並且我們可以透過這個表示方式得知點位在「直線的左側為圈」、「直線的右側為叉」這樣的答案。
普通的機器學習通常會將原本的資料做不只一次的轉換,例如先將資料轉成第一種表示方式,再將第一種表示方式轉成第二種表示方式,最後透過第二種表示方式的結果推出答案,這就是兩層(layer)轉換。當中的每個轉換方式通常是針對面對的問題精心設計過的,而由於轉換次數很少,一般又稱其為淺層學習(Shallow Learning)。
深度學習特別的地方就在於,它可以有成千上萬層轉換,但相較之下,每層轉換模式都相當類似,比較不須精心設計。最常見的情況就是把資料先向量化,然後每一層轉換都等價於對該向量乘上一個線性轉換矩陣,再做一個小的非線性變換,接著就進到下一層做一樣的事情,並讓程式隨著學習的過程,不斷地用應用數學方法去調整這些矩陣裡面的值,以達到模型的最佳化。這種涵蓋多層轉換的深度學習模型,又被稱作神經網路(Neural Network)。
現在深度學習的潮流會爆發,不只在於它能訓練出好的結果,也是由硬體的升級、網路時代興起使得能拿來訓練的資料量累積的夠多、一些核心數學演算機制被研究出來、有大量資金投入、開發框架讓入門的門檻愈來愈低等大量因素綜合起來的結果。
這章最後簡介了一些深度學習以外常見的機器學習理論,包含機率模型(Probablilstic modeling,最有名的就是線性迴歸)、核方法(Kernel method,一種分類演算法,它假設你可以找到一個 kernal 函數將低維度的資料轉化到高維度,並用高維度的 hyperplane 把資料區分開來。其中比較有名的方法是 SVM。)、決策樹(Decision Tree,透過一層層屬性分離的方式長出來的樹)、隨機森林(Random Forest,由多個決策樹組合起來,採取的方式類似拿所有決策樹的結果去投票並採多數決)、梯度提升(Gradient Boosting,常見的形容是三個臭皮匠勝過一個諸葛亮,至於讓臭皮匠進步的方法就是梯度下降法)等。
作者也講到在著名的數據分析比賽 Kaggle 裏頭,表現最好的兩個算法分別是深度學習和梯度提升,前者擅長辨識類問題,最常被用的框架是 Keras;後者則擅長處理結構化的資料,最常被用的框架則是 XGBoost。這本書給的程式碼範例都是用 Keras 寫的。
Ch2 The Mathematical building blocks of Neural Networks
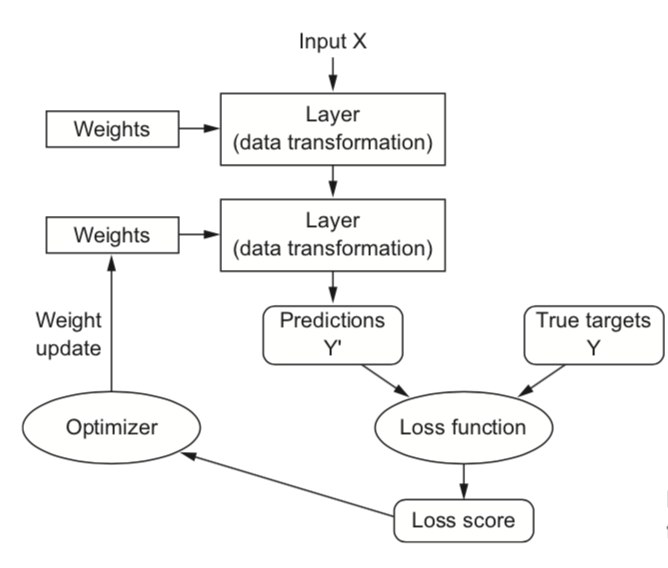
作者用 MNIST dataset 在 Keras 上實作了一個簡單的英文字母辨識模型,並介紹廣義的神經網路訓練流程:把輸入的資料向量化,經過多層運算後讓模型去預測出一個結果,把結果與真實值用一個損失函數(loss function)比對其差異,再用梯度下降法(Gradient Descent)和微積分的鏈鎖率(Chain rule)拿損失量(loss)去調整各層間的參數權重,試圖在一次次的訓練中讓損失達到最低。其中也介紹了 batch(每次餵給神經網的資料量) 和 epochs(全部的資料經過神經網訓練的次數)的概念,以及不同種類的梯度下降法(batch GD、mini-batch GD、SGD)。
這章的另一部分在介紹 numpy 的使用和張量(tensor)的運算。跟數學上定義比較不一樣的是,深度學習的張量概念想做的的其實只是把「資料的維度」具體化。比方說如果有一個 N 維向量,我們會把它稱作形狀是 (N) 的 1D 張量。如果有 M 個 N 維向量,換句話說,就是 M 個形狀是 (N) 的 1D 張量,依序排成一組,就把它稱作形狀是 (M,N) 的 2D 張量。同理,如果有 L 個形狀是 (M,N) 的 2D 張量依序排成一組,就稱其為形狀是 (L,M,N) 的 3D 張量。
這樣做的好處在於,在深度學習的世界中,資料都是用張量來表示:普通向量是 1D 張量、時間序列是 2D 張量、圖片是 3D 張量、影片是 4D 張量。透過 numpy 這個庫將這些張量資料存起來,再利用 GPU 平行處理實作張量運算,其效率會遠遠高於跑 for 迴圈處理資料。這也是當今深度學習能蓬勃發展的原因之一。
Ch3 Getting Started with Neural Networks
這章前半部在講 Keras 和工作站的架設,後半部則介紹了最簡單的神經網路:Sequential Dense Neural Network。Sequential 指的是每層 Layer 都是按順序接在前一個 Layer 上,Dense Layer 則是指最一般的連結方式:假設左邊有 M 個節點,右邊有 N 個節點,那總共就會有 M*N 個路徑將所有節點緊密連再一起。換句話說,每一層 Layer 的權重值都是由前一層 Layer 的所有節點上的值依照特定比例貢獻得到的。
作者用這類模型實作了幾個不同的問題,包含 Binary Classification(判斷是否的模型)、Single-Label Multiclass Classification(給定特定數量的類別,將每個資料分到其中一類)、Multi-Label Multiclass Classification(給定特定數量的類別,給每個資料上類別標籤)、Regression 等(輸入資料並輸出對應值)。實作的方法基本上都是先做資料預處理(data preprocessing),把它們變成可以餵給神經網路的張量形式。接著設定神經網的結構,把一層層 layer 串好、設定 optimizer(這邊使用的是 rmsprop,套用物理動量的概念在梯度下降法上,目的是避免讓最後的值跌到局部極小而非真正的最小值)等。
作者也針對不同問題適合選取哪一種的損失函數和激勵函數(activation function,就是層與層之間的非線性轉換,目的是增大輸出結果所在的假設空間大小,避免它淪為單純的線性空間)給出了基本的結論。舉例來說,Binary Classification 因為要給出一個機率值,最後一層輸出前的激勵函數適合用 sigmoid 函數搭上 binary cross entropy 來計算 loss;Multiclass Classification 適合 softmax 搭配 acc;regression 適合 ReLU 搭配 MSE(Mean Square Error)或 MAE(Mean Absolute Error)。
在每個實作過程中,可以看到一些基本的避免 Overfitting 的方法。Overfitting 指的是不小心讓機器學到太多你拿來訓練用的資料的特徵,使得它變得過於吹毛求疵,面對沒見過的資料時反而會判定失誤。打個比方,你要讓你的模型判斷一張照片是不是狗,於是你餵給它大量的狗照片,但這些照片裡的狗可能有些比較細微不重要的共同特徵,例如毛都偏黃、表情都吐出舌頭等。當你神經網的複雜度較低、訓練的 epochs 數較少時,基於資源和訓練次數有限,它會比較傾向去學習那些比較重要的特徵。然而當你的神經網太大、epochs 數太多時,它學到的判斷可能就太狹隘,認定一定要是偏黃吐舌頭的狗才是狗。
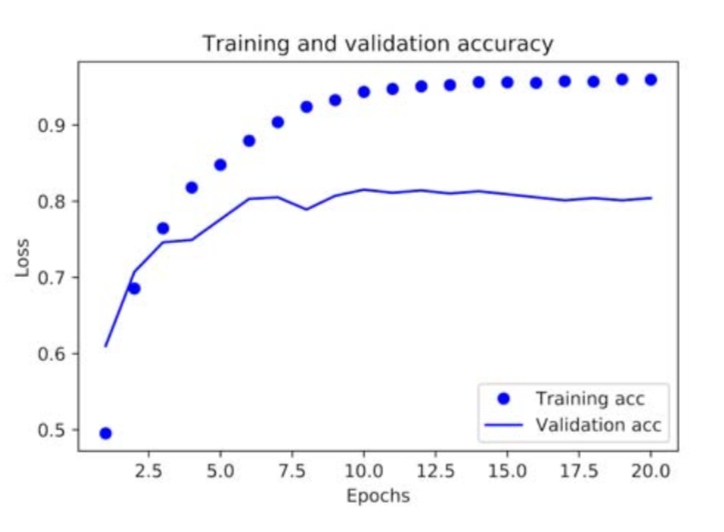
這章提供的避免 Overfitting 的方法有幾種,一是去調整你的神經網路大小(總層數和各層的節點數),不能讓它太大,以免有多餘的空間去學不必要的東西。二是把你的資料分成 Training、Validation、Test 三個 set。Training 和 Validation set 可以讓你在訓練過程中調整(tuning)出一個最適合的 epochs 數,而 Test set 則用來檢驗你的模型的準確率。而當你擁有的資料很少時,可以用一種更進階的 K-fold 的方式來分離你的 Training 和 Validation set。
另外一個還有跟 Overfitting 無關但需要避免的神經網路結構叫做 bottlenecks。概念上是不要在神經網中插入一個維度太低的 layer,因為它會導致整個資訊複雜度的流失。總體而言,我覺得讀完這章後,對於不同深度學習模型結構的基本特性會有一個蠻直覺的初步認識。
Ch4 Fundamentals of Machine Learning
這章分為四個部分:常見學習模式的介紹、Regularization(讓你的模型能對沒看過的資料依然表現良好,也就是指避免 Overfitting 的方法)、常見的資料預處理(Data Preprocessing)、廣義的深度學習實作流程(Universal Workflow),算是給了一個階段性的總結,我覺得寫的相當精彩。
書中提到的常見學習模式包涵了監督式學習(Supervised Learning)、非監督式學習(Unsupervised Learning)、自監督式學習(Self-supervised Learning)、增強學習(Reinforcement Learning)。監督式學習是深度學習的常見方法,適合做分類、迴歸、生成、預測、偵測等問題。非監督式學習適合用來做資料視覺化、壓縮、去噪、關係連結等,概念上是讓機器自己去找一些有趣的資料變換模式。自監督式學習是指在沒有人為上標籤的情況下的監督式學習,比較有名的是自編碼(autoencoder)。增強學習則是讓機器接收環境規則後,透過不斷試錯探索的方法找到最佳化的行為模式,像是下圍棋、玩遊戲等。
在 Regularization 這部分,除了前一章講的調整神經網結構、訓練次數外,這裏多補充了三個方法。第一是最直觀的「取得更多資料拿來訓練」。第二是 L1 & L2 Weight Regularization,第三是 Dropout。Weight Regularization 的概念是讓你每層 layer 在梯度下降的過程中權重衰減的更低,據說是受到奧坎剃刀理論所啟發。Dropout 則是在訓練的過程中適時的把資料的一部分內容拔掉,這有點像是把訓練一個大網路改成訓練很多個小網路,使得「大部分的小網路」不會出錯,依此給出一個相對準確的結果。
在資料預處理的小節,著重的點有 Value Normalization(把各個參數值等比例調到差不多的區間中)、Vectorization(將資料轉換成可以輸入訓練模型的張量)、Handling missing value(填補資料裡沒有值的位置)、Feature engineering(預先將資料轉換成一個比較好的表示方式,可以讓神經網的學習相對輕鬆、降低所需的資料量)。
至於這章最後的 Universal Workflow,作者給出的流程是: 定義你的問題 → 找到能判定你的模型好壞與否的標準 → 分好你的 Training set、Validation set 和 Test set → 資料預處理 → 設置你的模型,選取激勵函數、損失函數、優化器 → 增加訓練次數、調大你的神經網,讓你的模型 Overfit → 針對 Overfit 的模型做 Regularization
Ch5 Deep Learning for Computer Vision
這章講的是卷積神經網絡(Convolutional Neural Network,以下簡稱 CNN),它最常被應用的領域是圖像辨識。跟前面提的普通 Sequential Dense NN 差別在於,資料在進到 Dense Layer 前會先經過一塊卷積底(Convolution Base),將資料轉換成一個更有用的結構。
在講 Convolution Base 的運作前,先大略簡述一下它背後的精神。當你今天要判定一張圖的內容時,通常會先看它有哪些大型的特徵。同樣的,當你今天要判斷某個大型特徵是否存在時,方法也是去看它有哪些小型特徵。比方說今天有一張貓的圖,你之所以會知道它是貓,是因為它有貓耳朵、貓眼睛、貓鼻子、貓鬍子等大型特徵,而這些特徵以一個特殊的方式排列起來,所以看起來像貓。同樣地,你之所以知道一個大型特徵是貓耳朵,是因為你看到了幾條線以特定的方式排成了看起來像貓耳的三角形。
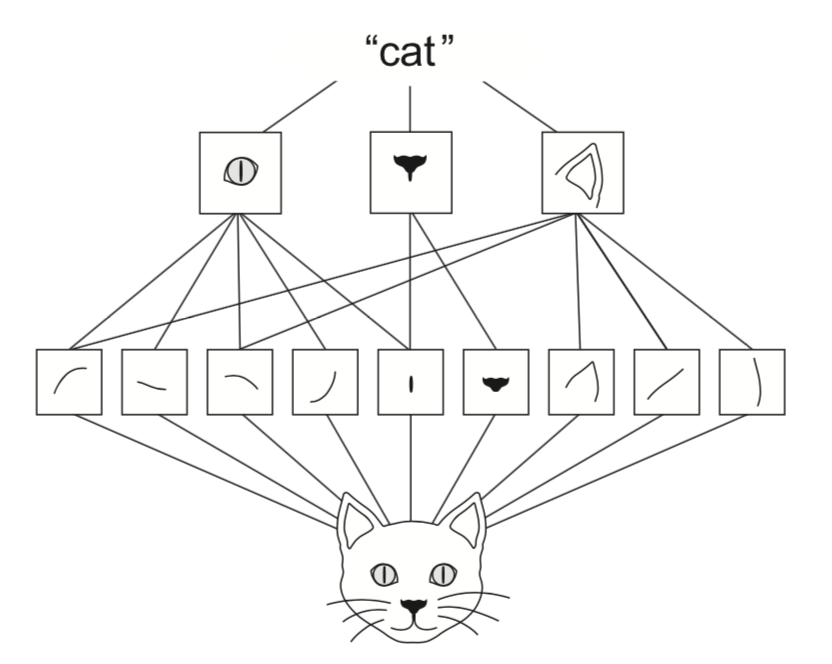
Convolution Base 在做的事情有點像是,給定一些不同的小型特徵,例如垂直線、橫線、圓圈之類的,透過運算找出這些小型特徵在整個圖上的分佈狀況。接著把原圖轉換成「各種小型特徵的分佈圖」,然後給定一些中型特徵,把「各種小型特徵的分佈圖」轉換成「各種中型特徵的分佈圖」,再給定一些大型特徵,把「各種中型特徵的分佈圖」轉換成「各種大型特徵的分佈圖」。最後你把這個涵蓋大特徵分佈的資料送進 Sequential Dense NN,訓練出來的結果就比單獨去看每一格 pixel 的內容有更好的準確率。
這裏舉個實際的例子。假設你今天有一張 150x150 pixels 的圖片,你首先會讓它通過一層二維的卷積層,如果你給這層設定的特徵數是 32,特徵大小是 (3,3),那就代表你將拿 32 個不同的 3x3 大小的小型特徵對這張圖上的所有 3x3 區域做內積(得到的值越大就代表這個區域的這個特徵越明顯),最後會得到 32 個 148x148 pixels 的圖,換句話說你會有一個形狀是 (148,148,32) 的張量。而為了得到中型特徵分佈,你會希望將「相隔較遠的特徵」之間的關係聯繫起來,一種作法是把一個 2x2 pixel 當作是 1x1 pixel 來看,這樣的作法稱作池化(Pooling)。常見的池化方法是最大池化(Max pooling),也就是把 2x2 pixel 裡面值最大的那個 pixel 當作代表選出來。因此前面提到的 (148,148,32) 的圖片張量如果被送進一個 (2,2) 池化層,輸出就會是 (72,72,32) 的張量。
把圖片送進一個卷積層,再送進一個池化層,得出的結果就等同於前面講的「各種小型特徵的分佈圖」。同樣的事情重複做好幾遍,最終你會得到一個格數較少但有不少「大特徵分佈」的張量。假若在通過最後一層池化層後,你輸出的張量形狀是 (7,7,128),意味著你把圖片轉換成一個 7x7 pixel、擁有 128 種大特徵分佈的資料。最後你可以把這個資料送進一個 Flatten 層,變成一個 7x7x128=6272 維向量,拿去餵給 Sequential Dense NN 訓練。
當然,這些所謂的拿特徵對圖片做內積的過程,歸根就底其實還是數學運算,因此你依然可以在訓練過程中透過鏈鎖率用梯度下降法去更新你的卷積層中各個特徵的內容,進而找到一些好的特徵出來,提升模型的準確度。
總結來說,當你在做圖片辨識前,先讓圖片經過好幾組「多個卷積層+一個池化層」,再將從最後一個池化層輸出的結果送進 Flatten 層平整成一維張量,最後送進普通的 Sequential Dense NN,你會發現這個訓練的準確率比直接把圖片平整化後送進 Sequential Dense NN 訓練所得出的準確率高出不少,因為它聯繫了圖片中的特徵間的排列關係,而這正是人類在辨識物體時的基本邏輯。
在介紹完基本的例子和 CNN 的原理後,作者花了些篇幅討論面對少量資料時的應對方式:資料擴增(data augmentation,透過將圖片做旋轉、拉伸等各種幾何變換來增加資料量)、使用一些別人訓練好的卷積底、微調(fine tuning,凍結大部分的卷積層,針對沒被凍結的卷積層做特別訓練)。同時本章最後也將 CNN 訓練出來的結果視覺化,展示了這個神經網究竟學了哪些特徵出來。
Ch6 Deep Learning for text and sequences
這章的重點在處理和訓練序列資料(Sequence Data),也就是那些「順序有意義」的資料,例如天氣隨時間的變化,或是當今很紅的自然語言處理(Natural Language Processing)等。一開始作者先講了兩個基本的文字資料預處理方式:one hot encoding 和 token embedding。one hot encoding 的作法是先選取常見的 10000 個英文單字,當系統讀到一個句子時,它就把這個句子轉換成一個維度 10000 的向量,裡面每一維的內容代表某一個常見單字在這個句子裡存在與否,0 是不存在,1 是存在。
token embedding 的作法則不太一樣。它的觀念是:假設我們現在賦予所有單字兩個維度,一個維度是從像狗科到像貓科,另一個維度是從已馴化到荒野化,則你會發現 cat、dog、tiger、wolf 這四個單字在這兩個維度的值皆不相同。token embedding 在做的正是賦予所有單字特定數量的維度,例如 300 維,這些維度一開始都是毫無意義的隨機值,但隨著機器訓練的過程中,它們的值會愈來愈有意義。一個句子(又可稱為一序列的單字)假設有 10 個單字,就可以視作是形狀為 (10,300) 的張量,裡頭的每個單字都是個 300 維向量。
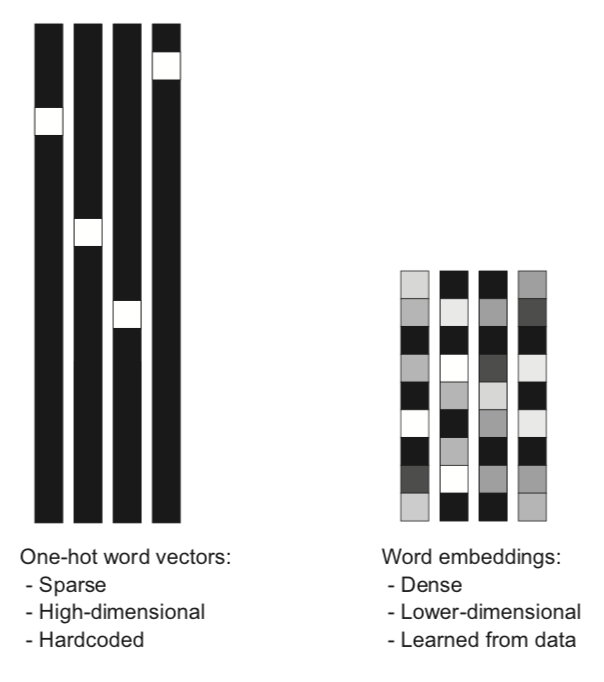
針對 token embedding,Keras 有提供 Embedding Layer,你只要把資料輸進去並調整好參數,就做完序列資料的預處理了。接著要做的就是訓練,而這章給出的第一個訓練模型為遞歸神經網路(Recurrent Neural Network,以下皆簡稱 RNN),概念為:以前的普通神經網,基本上就是輸入 input,得到 output。但在 RNN 裏頭,你是透過輸入這一次 input 和前一次的 output 來得到這一次的 output。假設 x 是輸入,y 是輸出,在數學上我們可以寫成這種形式:y_4 = f(x_4,y_3) = f(x_4,f(x_3,y_2)) = f(x_4,f(x_3,f(x_2,f(x_1,y_0)))) = …,某種程度上,這讓你的神經網獲得了「記憶」的功能。
一樣使用老方法,在把文字資料送進 Embedding layer,並將預處理的結果送進好幾層 RNN 後,你依然得把得到的結果丟到 Sequential Dense NN 裡訓練。這就是處理序列資料的基本款訓練模型。書中一樣提供了一些 RNN 相關的小技巧,像是 recurrent dropout、stacked RNN、Biderictional RNN(將資料從兩個方向都做一次 RNN,再將結果合併起來)等。不過我覺得特別重要的一點是,在使用這些特殊型態的訓練模型前,一定要至少先用普通的神經網訓練過,並記下你訓練出來的準確率作為底線,這樣你才會知道這些特殊模型是否真的適合你當下面臨的命題。
除了普通的 RNN 以外,作者也介紹了一些它的變形,像是長短期記憶模型(Long Short-Term Memory,簡稱 LSTM)和 GRU(Gated Recurrent Unit)等。基本的概念一樣,但當你今天要預測的資料內容所需要的「記憶」來自序列間隔比較遠的區間時,RNN 處理這種情況的能力就變得相當低。LSTM 和 GRU 正是為了解決這種長期記憶問題所存在的。
這章最後講的是從另一個角度去處理序列資料的方法:在 RNN 前面串上一維的 Convolution Base,可以讓你在更省資源的情況下達到良好的預測效果。
CH7 Advance Deep Learning best practices
這章基本上是快速的幫你把前六章的技術拓展開來。之前我們碰到的模型基本上都是 Sequential NN,差別僅在於中間要串 Dense、Convolution、Pooling、Recurrent、Embedding、Flatten……等各種不同的 Layer,然而真實情況下你不一定要讓所有 Layer 照順序排排站前後相接,而是可以用這些 Layer 組合出不同的拓樸結構。你可以將資料的一部分串 CNN,一部分串 LSTM,最後再把它們接起來。你可以設定多個 input 和多個 output、可以建立 Residual Connection(將很前面的 Layer 接給很後面的 Layer)來解決 bottleneck 的問題,還可以將某條分支的 Layer 分享給其他分支使用,這些都可以透過 Keras functional API 來實踐。
另一方面,這章也講了一些前面沒提過,但感覺蠻直觀的技術,像是 Batch Normalization(每次 SGD 時透過數學運算讓結果平均為 0、方差為1)、Depthwise Separable Convolution(把圖片的各個 channels 分離開來個別訓練)、Model Ensembling(將不同的 model 訓練出來的結果整合起來)、Hyper-parameter Optimization(將人工 tuning 的過程用程式自動化),不過都只是淺談而已,並沒有深入去講實作方法。
Ch8 Generative Deep Learning
這章也是一個相當精彩而且有趣的章節,它主要在講怎麼讓我們訓練的模型「生成」全新的資料,介紹的方法有以下五種。
LSTM:透過讓 LSTM 模型「預測」接下來的內容而不斷地生成新的資料。這個方法如果試圖去最佳化,容易產生重複的內容不斷遞迴出現的情況,因此作者在這邊介紹了一種調整模型「溫度」的概念,溫度愈高代表引入的隨機性愈多,能生成的結果自然會愈有趣,也更加難以預測。
DeepDream:這個方法是將已經存在的圖片丟進訓練好的 CNN,將圖片在某一層 Convolution Layer 的特徵給強化。

風格遷移(Neural Style Tansfer):作者在這裡定義了圖片局部的特徵叫「風格」(Style),通常可以在 CNN 比較前面的 Layer 看到。整體的結構分佈叫「內容」( Content),會出現在 CNN 比較後面的 Layer。Neural Style Tansfer 追求的就是用某張圖的風格畫出另一張圖的內容。也就是說,你需要一張「風格參考圖」和一張「內容參考圖」來生成最終想要的結果圖。在實作上,我們會將 loss 定義為 dist(style(ref_img) — style(generate_img)) + dist(content(original_img) — content(generate_img)),並試圖去最小化這個 loss。

變分自編碼器(Variational Auto-Encoder,簡稱 VAE):這個方法的概念是把一張圖片透過 encoder 送到潛在空間(Latent Space),的一個點,然後給這個點疊加一個微小的向量偏移,再透過 decoder 送回來變成圖片。例如你送一張普通人臉進去,加上一個「微笑向量」,輸出的圖片就是這個人在笑的樣子。VAE 假設的潛在空間是連續、結構化的,適合拿來做修圖,或是從 A 圖轉變成 B 圖的 GIF 動畫。

生成對抗網路(Generative Adversarial Network,簡稱 GAN):這個方法的概念是找一個訓練有素判斷鑑定家和一個專門生產偽造品的偽造家,讓偽造家努力的學習生產能騙過鑑定家的作品。實作上,你要訓練一個鑑定器(Discriminator)讓他學會辨識特定的特徵,例如一張圖片是不是狗。接著你訓練一個生成器(Generator),給予隨機的輸入,讓它輸出大量圖片,再把輸出的圖片送進鑑定器裡,如果鑑定器說「是狗」,這張圖片的 loss 就會很低;如果鑑定器說「不是狗」,它貢獻的 loss 就很高。GAN 會透過梯度下降法來調整生成器裡的參數權重以達到 loss 最小化的目標,這樣就能讓生成器在任意輸入下都能盡量生出像是狗的圖片。

Ch9 Conclusions
這是這本書的最後一章,作者總結了前幾章的重要內容、也談論了深度學習的局限性。他表示人類具備推論和抽象思考的能力,因而能在少量資料下做出正確決策,這是需要大量資料訓練的深度學習所無法做到的。當今的深度學習雖然能大幅改變世界,但它實質在做的只是兩個空間中的映射,離強人工智能(Artificial General Intelligence)還有非常遠的距離。
在未來展望部分,作者提出了許多我覺得相當有趣的觀點是,像是他認為在 RNN 中使用 for loop 來「記憶」只是一個開始,未來的神經網路如果添加了 if-else、while、variable、disk storage、sorting operators、各種 data structures 等概念,將有著比現在多非常多的可能性。另外他也提出未來的人工智能領域可能會像今天的軟體開發領域一樣,有著許多位能重複使用於各種專案的 global abstract library。
最後摘錄書末的一段話作為結尾:
Learning is a lifelong journey, especially in the field of AI, where we have far more unknowns on our hands than certitudes. So please go on learning, questioning, and researching. Never stop. Because even given the progress made so far, most of the fundamental questions in AI remain unanswered. Many haven’t even been properly asked yet.