淺談區塊鏈與比特幣
區塊鏈是什麼?區塊鏈和比特幣有什麼關係?

區塊鏈和比特幣是這幾年蠻火的詞彙,熱度大概跟人工智慧、神經網路不相上下,我自己也常在臉書上看到別人分享它們的相關訊息。然而截至目前為止,我對於我所看到的大部分區塊鏈相關資料都不是很滿意。
有些文章使用了大量比喻來解釋概念,讀完後好像有點懂了,卻又感覺不是很踏實。有些文章堆砌了一堆名詞,我根本不知道它想表達什麼。有些文章把局部的細節講的蠻清楚的,但總覺得少了些知識點連在一起的整體感。
即便是遇到鏈圈、幣圈的人,問了些問題後感覺也沒問出什麼所以然。這些人喜歡提的往往都是 ICO、白皮書的概念,或是「區塊鏈有多好的未來」之類的願景,但通常都不會好好地跟我解釋區塊鏈背後的技術細節。
直到最近,我挪了一些時間研究比特幣之父中本聰的《Bitcoin: A Peer-to-Peer Electronic Cash System》這篇論文,搭配網路上的眾多參考資源作為輔助,才總算對區塊鏈和比特幣有稍微完整一點的認識。
我不是區塊鏈專家,對大部分的虛擬貨幣並不熟悉,更不是什麼區塊鏈或比特幣的忠實信徒。會想寫這篇文章,單純只是想以一個圈外人的角度,談談我對「比特幣所使用的區塊鏈技術」的理解。
這篇文的目標,是依據我對於區塊鏈和比特幣的淺薄認知嘗試回答以下兩個問題:「區塊鏈是什麼?」、「區塊鏈和比特幣有什麼關係?」
區塊鏈、比特幣想解決什麼問題?
網路上大部分跟區塊鏈與比特幣有關的文章,都會先從一個「比特村」的故事開始講起,所以我也不免俗地用這個故事當作開頭,簡單的介紹一下區塊鏈和比特幣想解決什麼樣的問題。
有一個村莊叫「比特村」。在這個村莊裡,原本是由村長扮演著銀行的角色,每個村民都可以到村長那開戶、存錢。
假設 B 和 C 這兩個村民要交易,C 決定花 60 元向 B 買一包米,那麼 C 就會請村長從 C 自己的戶頭提出 60 元給他,並把這 60 元交給 B。B 收到這 60 元後,再請村長把它存進 B 自己的戶頭裡頭。
每次付款都要這樣提出、存入,難免會有些麻煩。所以 B 和 C 也可以選擇直接寫一筆交易單,上面表明「把 60 元從 C 的帳戶轉到 B 的帳戶」,並把交易單交給村長,讓村長依照上面的內容來更改 B、C 的帳本內容。
這種由村長管理大家的錢的方式,叫做「中心化管理」,現代的銀行體系就是基於這樣的管理機制在運作的。這種機制有個隱憂,就是村長必須要很有道德,讓大家願意相信他不會亂來、隨意修改大家的帳本謀取私利。另一方面,如果村長家失火,大家的帳本全被燒光了,全村的財產歸屬就會大亂。
有一天,一個叫中本聰的人來到了比特村。他發現村民們對於中心化管理帳本的擔憂,於是使用了一個叫「區塊鏈」的技術,希望能用它改造比特村的帳本管理方式。
比特村在引入了區塊鏈的技術後,帳本的管理從此就不再被村長壟斷了。現在每個村民都擁有一個網路帳戶,兩個村民想要進行交易時,他們只要把帳戶打開,在網路上建立一個「端對端」(Peer to Peer)的支付,交易就完成了,中間完全不需要村長作為中介。
除此之外,每個村民的帳戶都會保存著一份全村完整的交易紀錄表。一旦新的一批交易產生,每個人帳戶裡頭的這份交易記錄表就會自動更新。如果 A 不小心弄丟了他的交易紀錄表,他可以隨時跟其他村民拷貝一份回來,這樣就不用擔心交易紀錄表不見或損毀的問題了。
與此同時,因為大家都有相同且完整的交易紀錄表,所以如果 B 偷偷將「把 60 元從 C 的帳戶轉到 B 的帳戶」這筆交易改成「把 70 元從 C 的帳戶轉到 B 的帳戶」,那麼他手上的交易紀錄表就會和其他人的不一樣,大家就會知道 B 的交易紀錄表是被竄改過的(參見下圖)。
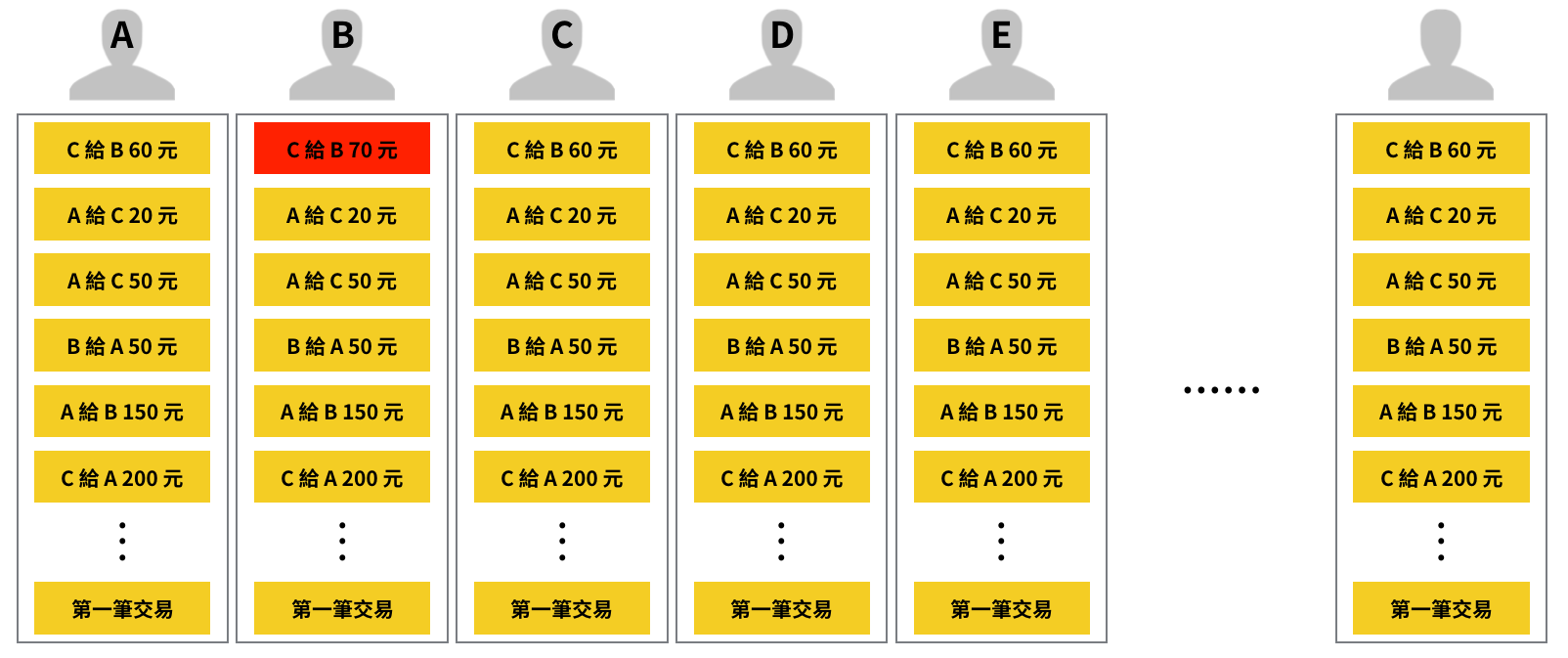
區塊鏈和比特幣是什麼?在比特村裡,區塊鏈就是這個交易紀錄表,只要有一群人在一起,便可以用這種區塊鏈的技術來管理帳本。
在區塊鏈技術下,每筆交易所使用的貨幣單位就是「虛擬貨幣」,而世界上第一個應用了區塊鏈技術的去中心化帳本管理系統,它所使用的虛擬貨幣就叫「比特幣」。
(註:在這篇文章裡頭,所有的當我說「100元」時,這裡的「元」指的都是比特幣,只是方便起見用比較口語化的方式來描述。)
不同的虛擬貨幣體系在規則上會有些微差異,本文在介紹區塊鏈的原理時,皆以比特幣的規則為準。
對區塊鏈比較熟悉的人可能會發現,我在開頭的這個介紹裡並沒有解釋什麼是「區塊」和「挖礦」。這是因為這個介紹把區塊鏈的概念做了大幅簡化,它的目的只是要讓你對「區塊鏈和比特幣希望做到什麼事情」有初步的了解。
接下來我會講解區塊鏈所使用的幾項重點技術,然後一步步把這些技術和區塊鏈的概念整合起來,讓你能比較完整地看到它底層的運作過程。
非對稱式加密與公私鑰系統
在深入分析區塊鏈的交易紀錄前,我們需要先學一個密碼學的先備知識:非對稱式加密與公私鑰系統。
密碼學的領域有對稱式加密和非對稱式加密這兩個分支。在談這兩個加密的差別之前,我先回答一下「什麼是加密?」這個問題。
所謂加密,就是把一段我們能讀懂的訊息,用某種方式轉換成一段我們看不懂的訊息。解密,則是把我們看不懂的訊息,轉換回我們看得懂的訊息。
以最簡單的「凱薩密碼」為例:假設要把「hello」這個訊息加密,我們可以將這個字串裡頭的每一個字母都向後移動一位,變成「ifmmp」,這就是一種加密方法。
在這個例子裡頭,「hello」是明文,「ifmmp」是密文,「把字母向後移動一位」則是這個凱薩加密法的「鑰匙」。凱薩加密法一共有 25 把鑰匙,分別是「把字母向後移動一位」、「把字母向後移動二位」、……、「把字母向後移動二十五位」。
當有人收到了「ifmmp」這段密文後,如果他知道這是用凱薩加密法加密過的密文,那麼他就會需要從這 25 把鑰匙裡頭,拿出「把字母向後移動一位」這把鑰匙,用它將密文解密。
這就好像我們把一個東西放進置物櫃後,會用一把鑰匙插進去鑰匙孔,順時針旋轉將櫃子鎖了起來。當我們要把東西從置物櫃拿出來時,則會將同一把鑰匙插進去鑰匙孔,逆時針旋轉打開置物櫃。這種使用同一把鑰匙的加密機制,就叫「對稱式密碼學」,比較著名的演算法有 DES、AES、RC6 等。
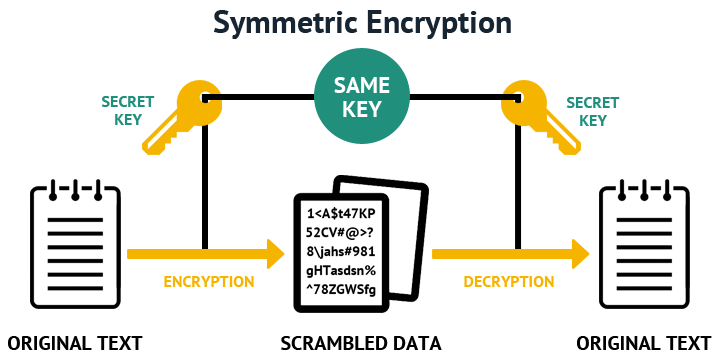
對稱式密碼學有個問題,就是當你在加密和解密時,用的是同一把鑰匙。但在現實中,很多時候你會想把這兩件事情分開,這個時候「非對稱式密碼學」就派上用場了。
在非對稱式密碼學中,我們會有兩把鑰匙,一把叫公鑰,另一把叫私鑰。當一段訊息被用公鑰加密後,它只能被私鑰解密。同樣地,當一段訊息被用私鑰加密時,它也只能被公鑰解密。
在這樣的機制下,你可以把公鑰公開出去,把私鑰自己收著。如果別人要傳訊息給你,他們會用你的公鑰把訊息加密傳給你,但只有你能用你的私鑰把訊息解密,查看內容。而當你要對外發布訊息時,你可以用私鑰把訊息加密後發出去,外界如果能用你的公鑰把密文解開,他們就能確定這個訊息真的是你發的。
一個合格的公私鑰系統,必須滿足一個很重要的條件:當你得到公鑰時,你沒辦法由公鑰的內容破解出私鑰,反之亦然。RSA、ECDSA 等非對稱式密碼學中比較著名的演算法,它們透過數學理論來確保人們沒辦法破解出私鑰的內容,以保證系統的安全性。值得一提的是,比特幣的系統所使用的公私鑰演算法就是 ECDSA。
本文後面會談公私鑰技術與區塊鏈的關係,但現在你只需要知道公鑰和私鑰是什麼就好了。如果想更深入暸解非對稱式密碼學的細節的話,可以看我在下面舉的這個例子,它解釋的是 RSA 的公、私鑰生成原理。
首先隨機生成兩個大質數 p、q,並且訂出兩個數 N、r,其中 N = p×q,r=(p-1)(q-1)。接著選取一個比 r 小並且與 r 互質的數字 e,然後找出一個數字 d 使得 e×d (mod r) = 1。到這裡為止,我們可以觀察到兩件事情。
第一,因為 N 只有 p,q 這兩個質因數,所以根據中國剩餘定理和算數基本定理的論證,我們可以證出 r=φ(N),這裡的 φ 指的是歐拉函數,代表比 N 小且與 N 互質的正整數的數量。
第二,因為 e×d (mod r) = 1,所以 e×d 一定是 r 的倍數加 1。
歐拉定理指出,對於任意正整數 k 而言,如果 k 和 N 互質,那麼 k 的 φ(N) 次方 mod N 一定會等於 1。由於 r = φ(N),所以 k 的 r 次方 mod N 等於 1。又由於 e×d 是 r 的倍數加 1,所以 k 的 e×d 次方 mod N 一定會等於 k 自己。
於是我們可以把 (N,e) 當作公鑰,(N,d) 則是相對應的私鑰。當現在有一個訊息從電腦輸入時,電腦最終會把它轉換成某個數字 k,這個 k 被稱作明文,意思是沒被加密過的資料。
把 k 取 e 次方 mod N 後得到數字 c,c 就是「用公鑰 (N,e) 把 k 加密的結果」,也就是密文。當你再把 c 取 d 次方 mod N,你就會重新得到 k,這個動作叫「用私鑰 (N,d) 將密文 c 解密回明文」。
當你擁有 N 和 e 這兩個數字時,若要求出 d 的值,你必須要知道構成 N 的兩個大質數 p 和 q 的值,這意味著你需要先將 N 做質因數分解。但是當 p,q 很大時,把 N 質因數分解的難度就會變得非常大,以 RSA-2048 為例,它的 p,q 都是在二進位下 2048 位的質數,即便用電腦做暴力搜索,也要花上好幾年的時間。除非量子電腦的發展足夠成熟,否則現有的硬體設備基本上無法在短時間內透過公鑰來破解私鑰內容。
交易紀錄,由私鑰擔保
現在我們回到比特村,準備來看公私鑰系統對新的帳本管理系統有什麼幫助。不過在談公私鑰系統的功用之前,我們得先大致暸解一下真正的區塊鏈是怎麼管理交易紀錄的。
在區塊鏈的系統裡,每一個人都至少會有一個帳戶,「帳戶」是交易的最小單位。任何人都可以選擇辦理很多個帳戶,但現在為了方便講解,我們就假設比特村裡的每個人都只有一個帳戶。
在以前由村長主持的中心化帳本系統中,帳戶是用來「存錢」的。當你要交易時,你就會轉帳,把一定量金額從你的帳戶轉到其他人的帳戶裡頭,你的帳戶餘額會隨著一筆筆的交易完成而改變。
但在區塊鏈去中心化的帳本系統中,帳戶是用來「存取交易紀錄」的。也就是說,你可以在你的帳戶裡頭,檢視每一筆跟你有關的交易,然後由系統統一計算這些交易裡的數字,得出你的餘額。
在每一筆帳戶之間的交易裡頭,系統都會要求輸入欄位和輸出欄位。
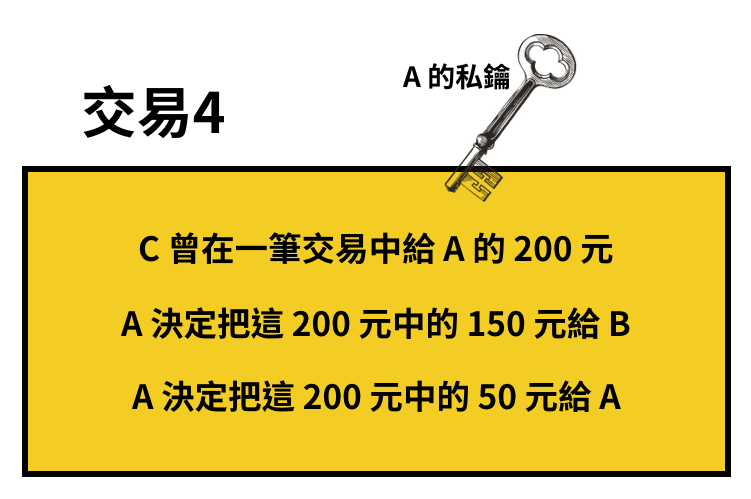
舉例來說,現在系統裡已經有了三筆交易,而此時 A 想要給 B 150 元,讓「A 給 B 150 元」變成第四筆交易。要完成這筆交易,A 需要有錢,接著才能把錢給 B。
錢從哪裡來?系統於是開始查 A 以前的交易紀錄,發現在交易 3 裡,C 曾給 A 200 元。於是系統便把「A 在交易 3 收到的 200 元」當作交易 4 的輸入,並在交易 4 的輸出欄位寫下:
- A 決定把這 200 元中的 150 元給 B
- A 決定把這 200 元中的 50 元給 A
以上的寫法只是為了方便描述。在真實情況中,系統不會直接在交易內容裡寫下 A、B 的名字,而是會寫下 A 的帳戶地址和 B 的帳戶地址。當外界的人看到這筆交易時,他們只會看到兩個帳戶在做交易,但除非 A、B 主動對外公開自己的帳戶地址,否則外界不會知道這兩個帳戶的擁有者是誰。
交易 4 的輸入和輸出欄位都填寫完成後,系統接著要做的就是讓其他帳戶知道 A 和 B 完成這筆交易了,這樣大家才能把這筆交易紀錄更新到自己的交易記錄表裡頭。
但是這裡出現了一個安全性問題:其他人要怎麼判斷這筆交易真的是 A 發起的呢?要是有人在中途把這筆交易攔截下來,然後竄改裡面的內容,大家不是就會接受到錯誤的資訊了嗎?
公私鑰系統此時就派上用場了。A 會拿出自己的私鑰,把這筆交易內容加密,然後附上他的公鑰,再把交易廣播出去讓大家知道。其他人此時會拿 A 的公鑰把這筆交易解密,如果解得開,那這筆交易就一定是 A 發起的,因為只有他擁有私鑰。
要是有人在中途把交易解密後竄改內容,因為這個人沒有 A 的私鑰可以重新加密,所以他竄改後的東西是無法通過公鑰驗證的。由此可見,公私鑰系統的角色,就在於確保交易的真實性,防止有心人士在中間搗亂。
UTXO 帳本模型,一切回歸交易本質
我們前面提到過,在區塊鏈帳本系統中,系統對於帳戶之間的每一筆交易都會要求輸入欄位和輸出欄位。輸入欄位就是你要交易的錢,這筆錢是從「之前的交易」裡取得的。輸出欄位則是你要把這筆錢的一部分給別人,剩下的留給自己。
在這個系統中,帳戶是用來存取交易紀錄的,餘額則是根據交易紀錄算出來的。這種記帳模式,被稱作 UTXO 帳本模型。
我們接下來用一個稍微複雜一點的例子來介紹這個帳本模型的特性。
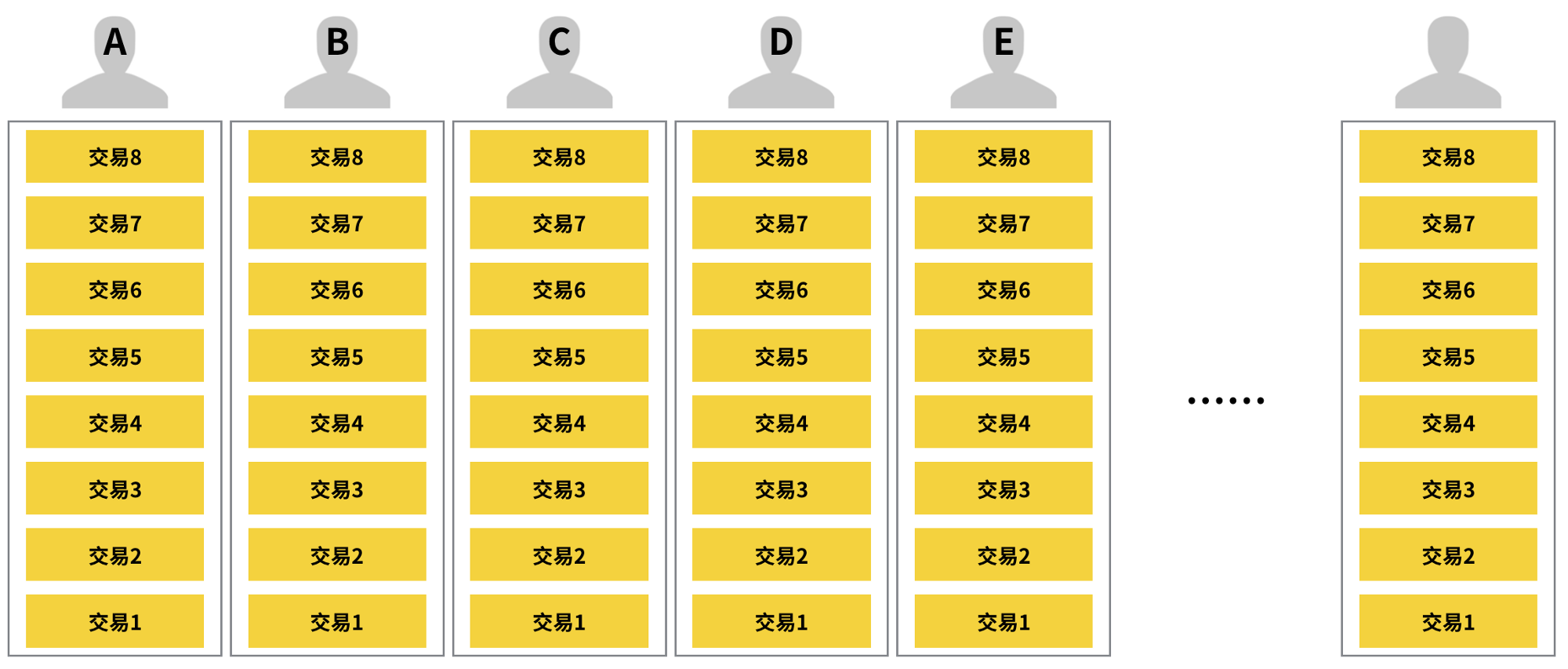
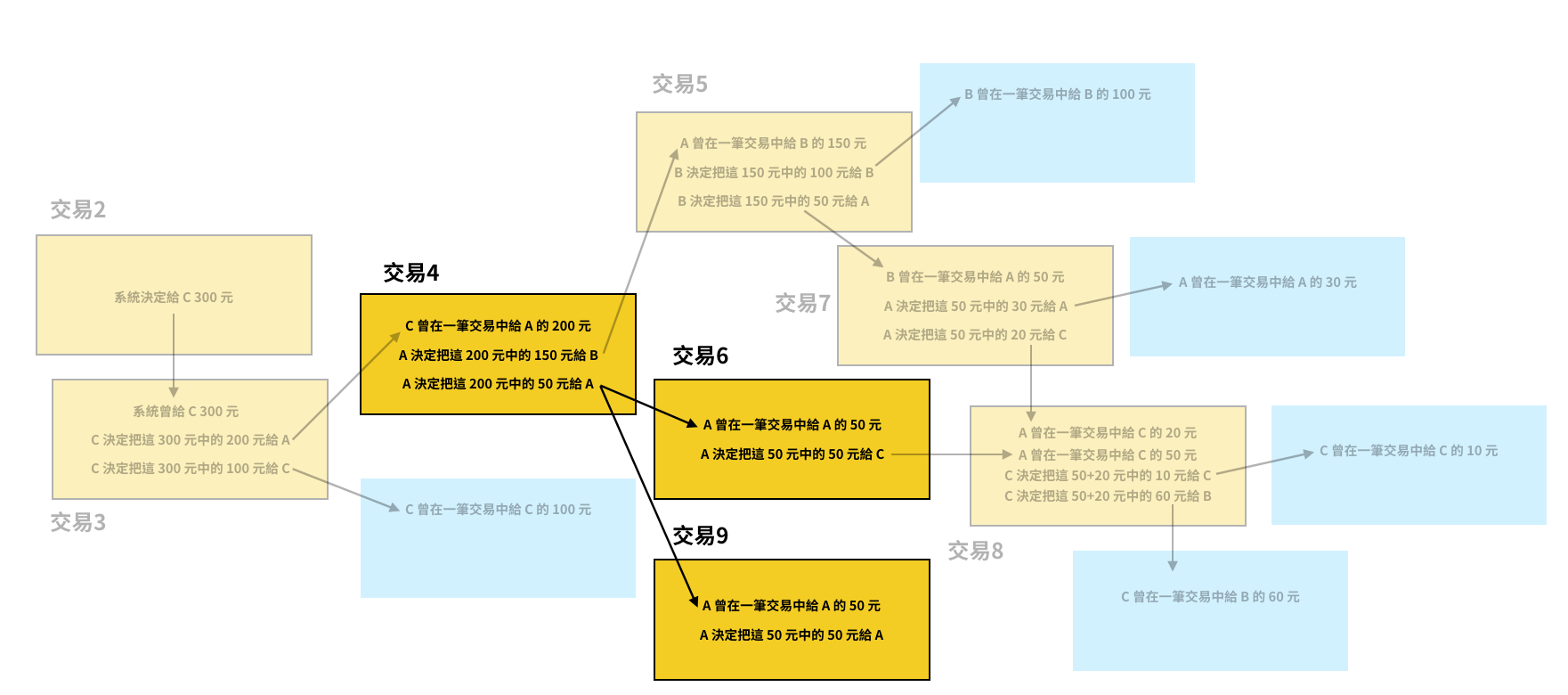
比特村裡有 A、B、C、D、E……等很多人,這些人共用了同一個區塊鏈帳本,而這個帳本裡頭目前一共有八筆交易紀錄。
在交易 1 裡,系統給 D 分配 200 元,在交易 2 裡頭,系統給 C 分配了 300 元。此時 A 和 B 沒有進行過任何交易,所以他們都沒錢。
在交易 3~8 裡,A、B、C 三人進行了一連串的交易。首先 C 想要跟 A 買羊毛,需要花費 200 元,於是系統把 C 在交易 2 中獲得的 300 元當作輸入,從裡頭分出了 200 元給 A,剩下 100 元留給 C,成功完成交易 3。
A 現在想要跟 B 買電影票,需要花費 150 元。於是系統把 A 在交易 3 中獲得的 200 元當作輸入,提出 150 元給 B,50 元留給 A,完成交易 4。
B 想跟 A 買一顆棒球,需要花費 50 元。於是系統把 B 在交易 4 中獲得的 150 元當作輸入,提出 50 元給 A,100 元留給 B,完成交易 5。
A 想跟 C 買一本書,需要花費 70 元。但 A 現在只有在交易 4 留下的 50 元和在交易 5 獲得的 50 元。為了買書,洗統決定用兩次交易來幫 A 完成付款。
它首先把 A 在交易 4 中留給自己的 50 元當作輸入,全部提出來給 C,完成交易 6。接著再把 A 在交易 5 中獲得的 50 元當作輸入,提出 20 元給 C,30 元留給 A,完成交易 7。
C 想跟 B 買一包米,需要花費 60 元。系統這時有兩個選擇,一個是把交易 3 留給 C 的 100 元當作輸入,提出 60 元給 B,40 元留給 C。另一個是把 C 從交易 6 獲得的 50 元和從交易 7 獲得的 20 元,一共 70 元當作輸入,提出 60 元給 B,10 元留給 C。這兩種方法都可行,系統隨機選了其中一個方法,完成了交易 8。
以下這張圖顯示了每一筆交易彼此間的關聯。橘色方塊代表已完成的交易,藍色方塊則代表著未來新的交易產生時,這些新交易的輸入欄位可接收的金額。
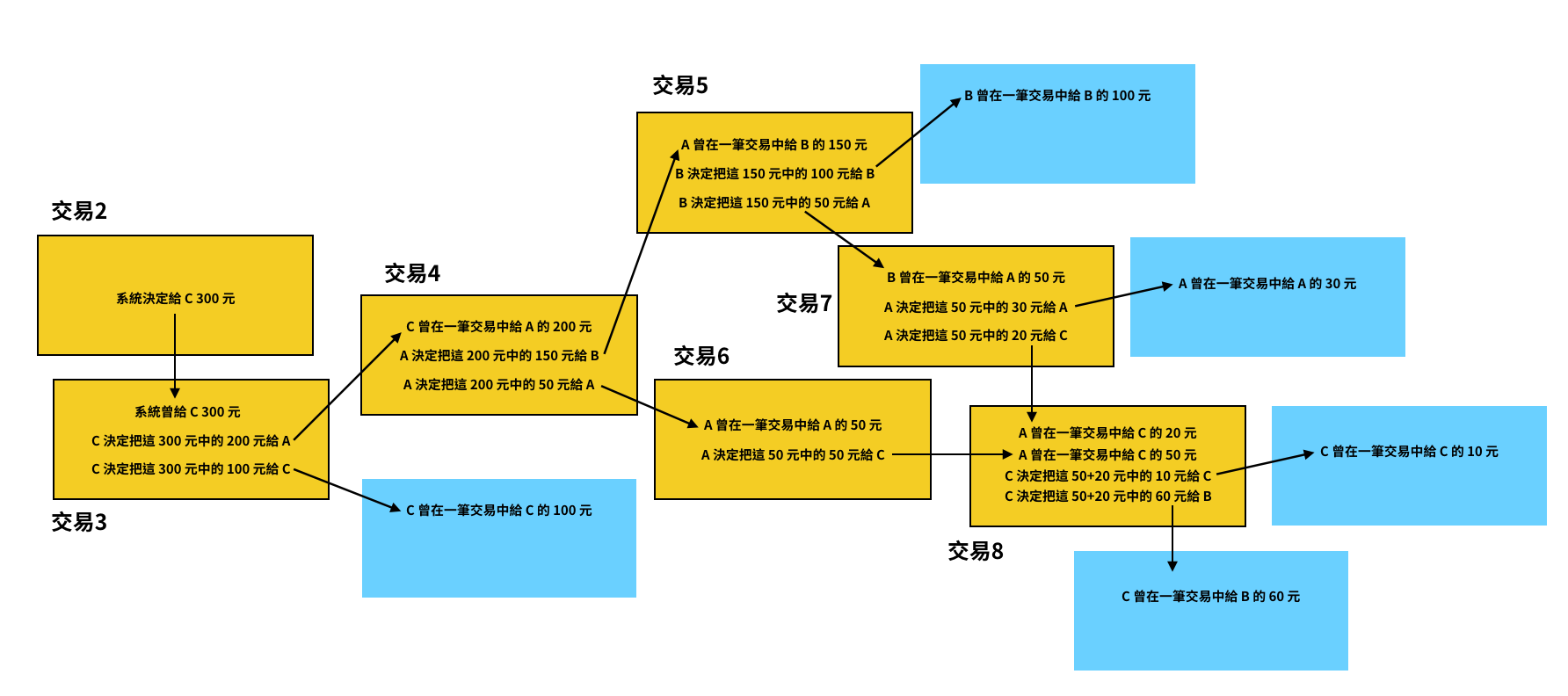
到目前為止,系統已經完成了八筆交易, 比特村裡的 A、B、C、D、E……等所有人都擁有這八筆交易的資訊。如果 A 打開自己的帳號,系統會特別把 A 參與過的交易紀錄顯示出來給 A 看,也就是下圖黃色方塊標示的交易 3、4、5、6、7。系統會根據這些交易紀錄算出 A 帳戶的所剩餘額是 30 元。
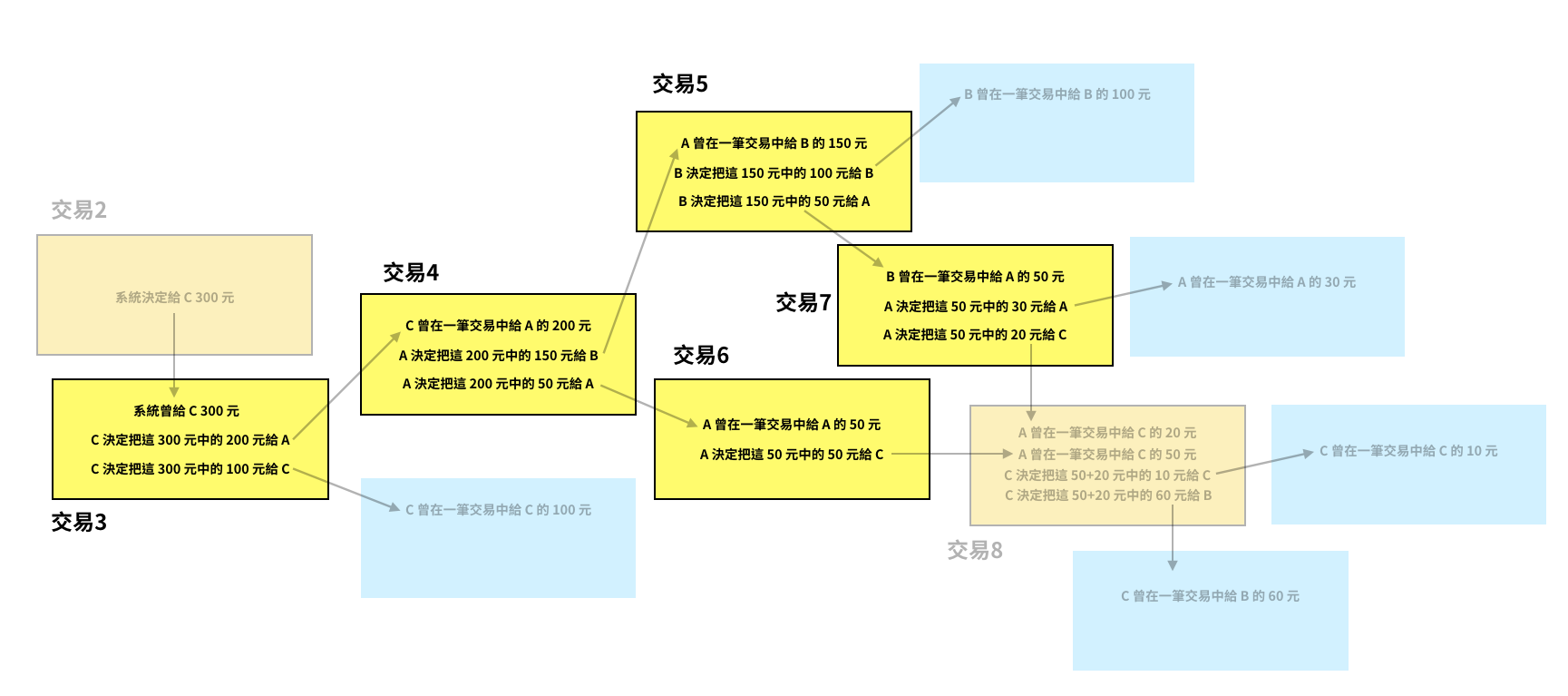
當 B 打開自己的帳號時,他會看到自己參與過交易 4、5、8,系統算出來的餘額是 160 元。
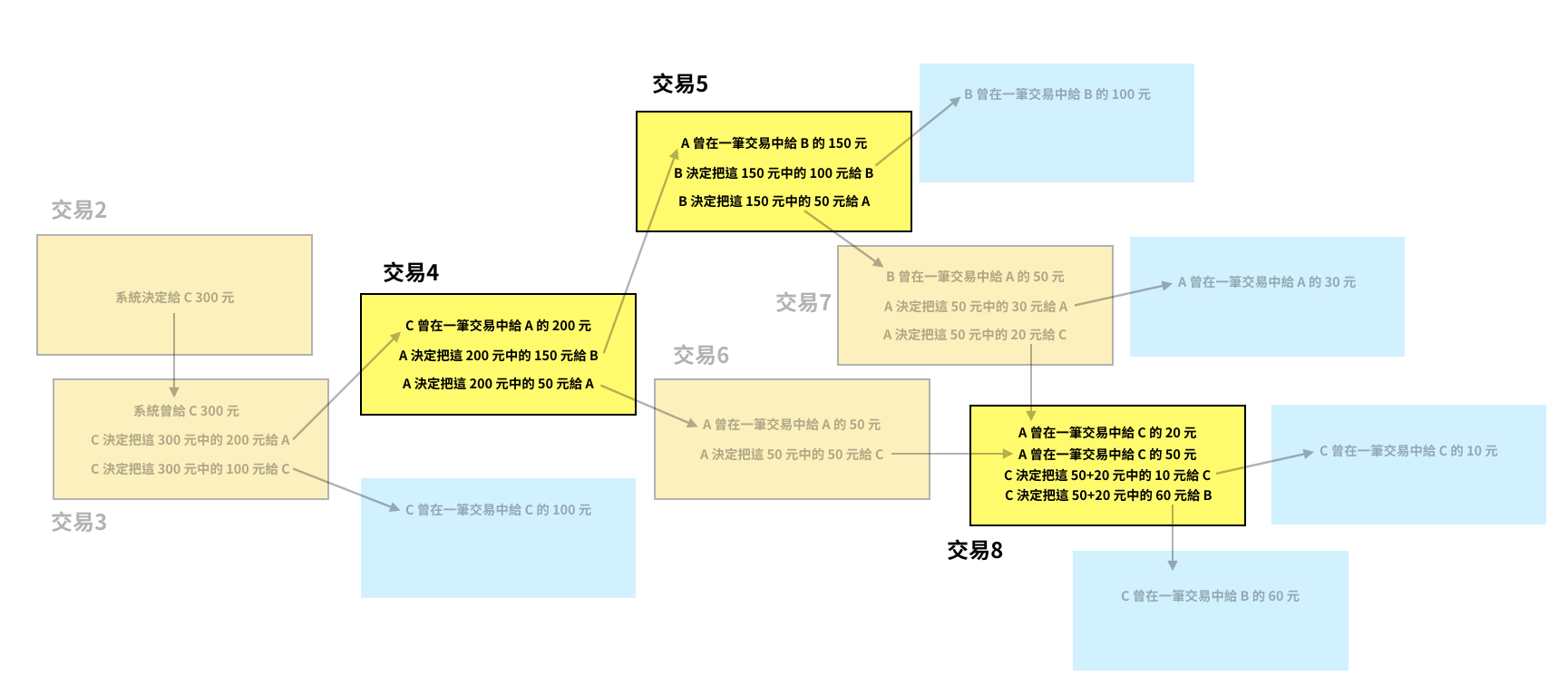
當 C 打開自己的帳號時,他會看到自己參與過交易 2、3、6、7、8,系統算出來的餘額是 110 元。
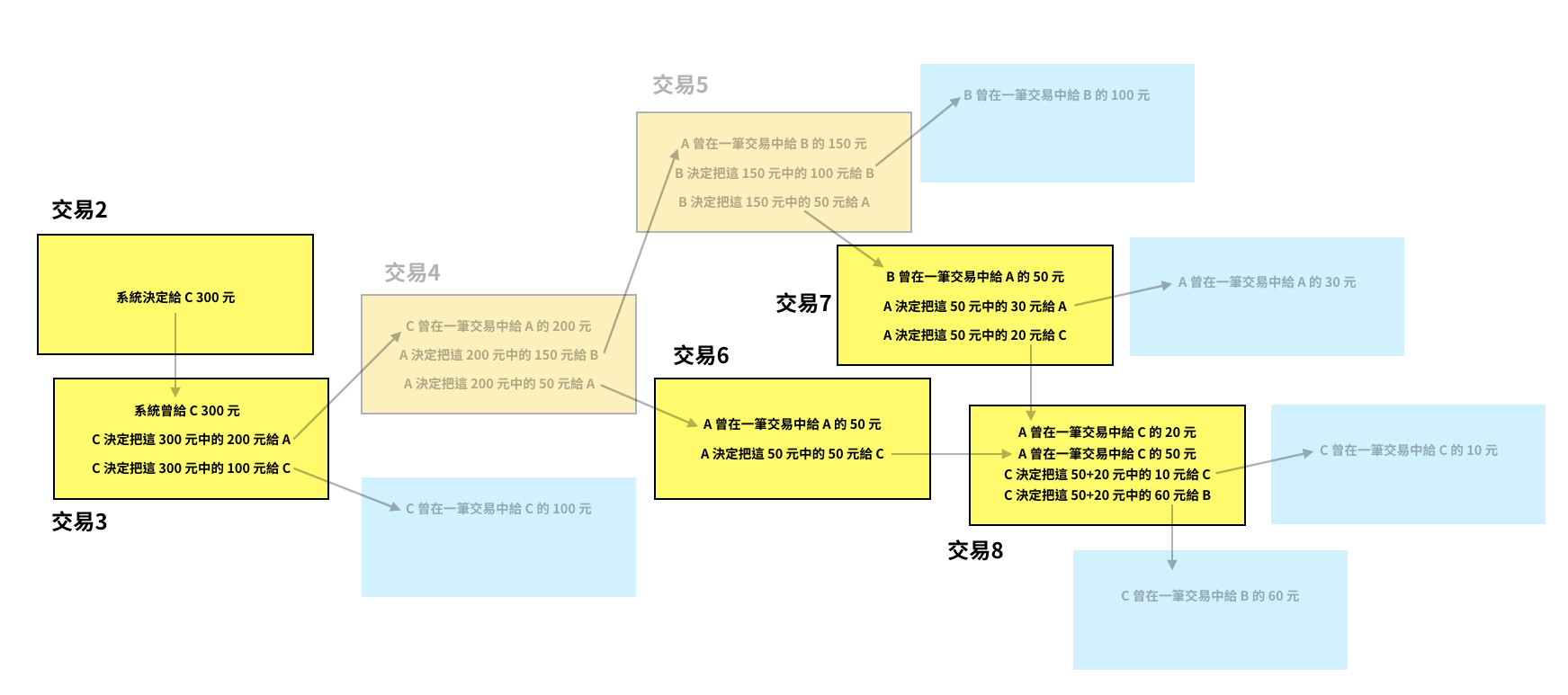
把 A、B、C 的餘額相加,會得到 30 + 110 + 160 = 300 元,這剛好就是 C 在最一開始擁有的金額量。在真實場景中,系統會針對每筆交易收一點手續費,所以有些比特幣是會隨著交易回流到系統裡頭的。
雜湊函數,把一切變成固定長度的亂碼
現在我們對區塊鏈和比特幣的交易原理已經有初步的暸解了。但是有一個問題還沒被回答:究竟什麼是區塊?
在回答這個問題前,必須先介紹一種在密碼學裡很重要的函數,稱作雜湊函數(Hash function)。雜湊函數有什麼特性呢?如果 h 是一個雜湊函數,z 是一個任意長度的數值,且 h(z) = x,那麼這個 x 就是 z 被 h 雜湊(hash)後的 「hash 值」,且 x 的長度會是固定的。
以下是雜湊函數的幾個主要性質:
- 沒辦法用數學運算的方式由 x 的值回推出 z 的值。
- 要找到一個值 y,使得 h(y) = x,最好的方法只有用暴力搜索不斷的嘗試。
- 對任意的 z,如果只做一點點的修改,例如讓 z’=z+1,它們 hash 後的結果差距會大幅發散,h(z) 和 h(z’) 的值一點也不接近。
下面是維基百科裡的一個雜湊函數範例,你會發現任意長度的字串在被雜湊函數 hash 過以後,得到的 hash 值長度都一樣。
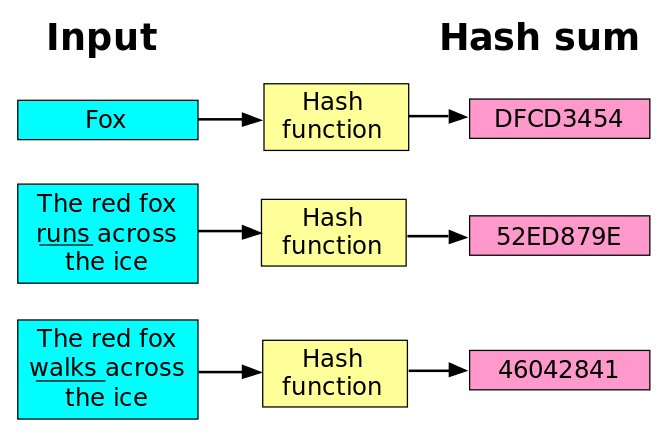
在比特幣的規則裡,系統所使用的雜湊函數叫 SHA256,不論你輸入什麼內容,它都會輸出一個二進位下長度 256 bits 的數字。根據 1Bytes=8 bits 的換算,用 SHA256 算出來的 hash 值,在記憶體中佔據的空間大小皆是 32 Bytes。
以下是 apple、Apple、orange、Orange 這四個英文單字在被 SHA256 hash 後的輸出,以 16 進位表示出來的樣子。你可以看到光是把開頭的字母從小寫換到大寫,它們對應到的 hash 值就會產生非常大的差異。
- SHA256(“apple”)=3A7BD3E2360A3D29EEA436FCFB7E44C735D117C42D1C1835420B6B9942DD4F1B
- SHA256(“Apple”)=F223FAA96F22916294922B171A2696D868FD1F9129302EB41A45B2A2EA2EBBFD
- SHA256(“orange”)=7EB7F358DECB954ACAEF10BA4249456D2359F3256EEFD6D4A914DA39D85F8776
- SHA256(“Orange”)=78E7771B8B46E11DDB34BA48887E1330525215F96D94778980D1186E6F09F6B4
礦工們,該打造區塊囉
知道了什麼是雜湊函數以後,現在我們可以來解釋區塊鏈了。
區塊鏈,就是用來保存交易記錄的一條長鍊。這條長鍊上有一個又一個的區塊,每個區塊裡都包含著成百上千筆交易紀錄。
新的交易無時無刻都在產生,而系統會指定某些人把這些交易紀錄打包成區塊,用區塊來盛裝這些交易記錄。
在比特幣的系統中,大約每十分鐘就會生成新的區塊。只要新區塊一被做出來,系統就會把它廣播給所有其他帳戶,讓所有人更新自己的區塊鏈。
在現實的情況下,每個區塊所包含的交易紀錄數量都會有些差異,主要取決於當時新生成的交易數量,但通常上千筆跑不掉。本文為了方便描述,我們在這就先假設每個區塊剛好都存放著四筆交易紀錄。
負責把新的交易記錄批量打包成區塊的人,被稱作「礦工」,他們有兩個主要任務。第一,使用每一筆新的交易附帶的公鑰,驗證這些交易是否有效。第二,把這些交易打包在一起變成區塊,每個區塊都會包含「區塊頭」和「一批交易紀錄」這兩個部分。
當礦工把區塊打包好後,會在這塊區塊上簽名,表示「這個區塊是我做的」,系統看到後便會給礦工一點比特幣當獎勵。
我們現在有一批準備要打包的交易紀錄了,要怎麼生成它們的區塊頭呢?雜湊函數這時就派上用場了。雜湊函數在這裡的第一個功用,是幫助準備打包成區塊的那幾筆交易找出一個值,這個值被稱作是該區塊的 Merkle Root,是區塊頭的一部分。
假設礦工現在要把 L1、L2、L3、L4 這四筆交易打包成一個區塊,他必須先得到 L1~L4 的 Merkle Root,原因會在後面解釋。要求出 Merkle Root,礦工需要先把這四筆交易的內容各自取 hash,得出四個 hash 值。
接著礦工得把 hash(L1) 和 hash(L2) 加起來,再對它取 hash,得到的值為 hash(hash(L1)+hash(L2))。同樣地把 hash(L3) 和 hash(L4) 加起來,對它取 hash,其值為 hash(hash(L3)+hash(L4))。最後把這兩個新得到的值加起來,然後取 hash,得到的值就是 Merkle Root。
所以如果礦工要把 L1、L2、L3、L4 這四筆交易打包成一個區塊,那麼這個區塊的 Merkle Root 值,就是 hash(hash(hash(L1)+hash(L2))+hash(hash(L3)+hash(L4)))。
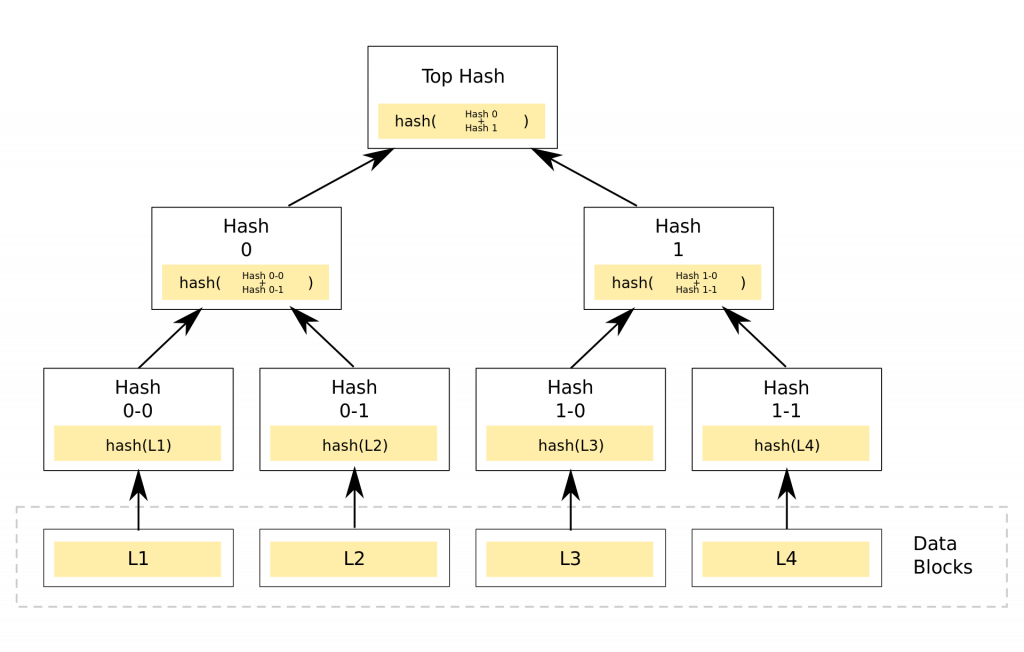
Merkle Root 有什麼用呢?它可以保證這個區塊內的交易紀錄無法竄改。假設有個人偷偷的把 L2 的內容改變了,那麼根據雜湊函數的發散性,hash(L2) 的值會有大幅改變。這個改變會一路往上傳,讓 Merkle Root 的值也產生大幅改變。
如果有一個人要查詢 L1 的交易內容,他的查詢方式會是:先找到 L1 的所在區塊,把這個區塊內的所有交易內容抓出來,重新算一遍 Merkle Root,看看算出來的 Merkle Root 值跟區塊頭上標示的 Merkle Root 值是不是相同。如果相同,那麼 L1 的內容就是沒被竄改過的;如果不同,那麼 L1~L4 當中一定有交易被竄改過,這時他就可以去找拿其他人的區塊鏈過來比較,看看到底是哪個交易被竄改了。
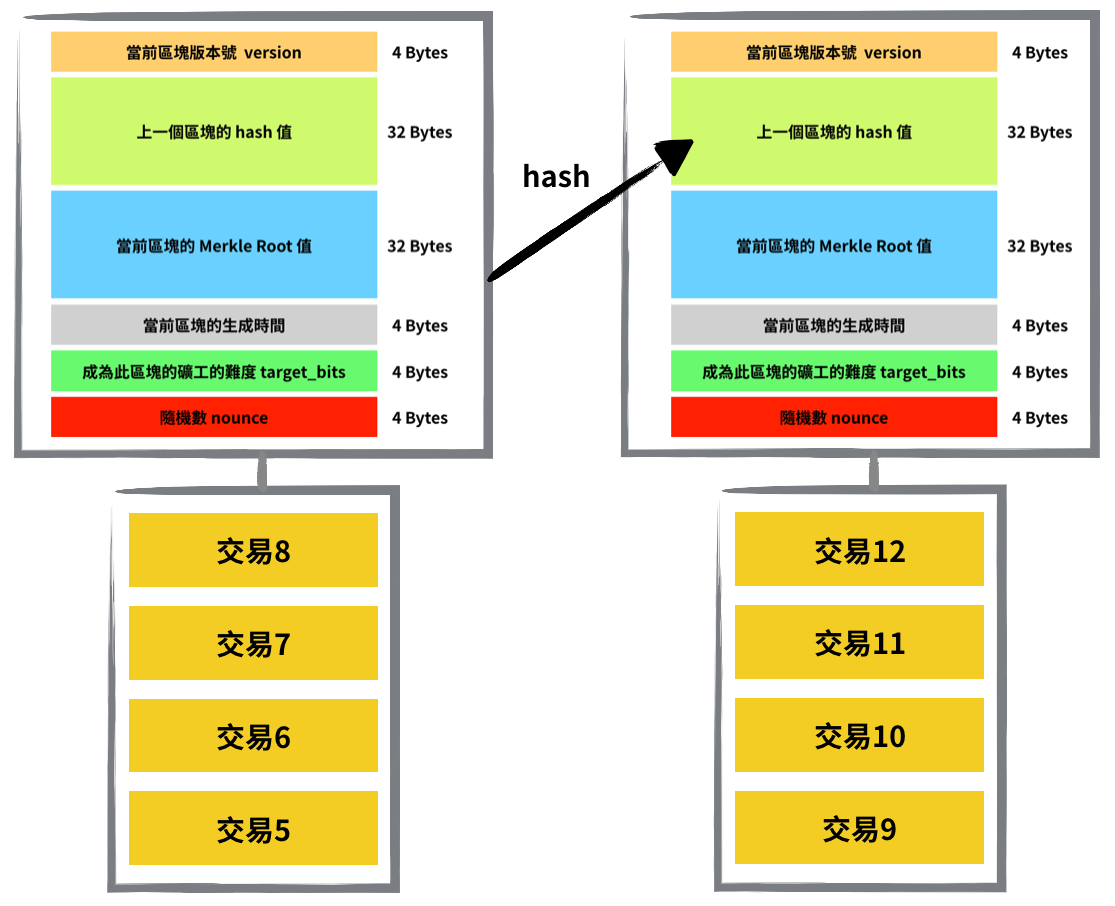
參考下面這張簡化版的比特幣區塊鏈結構圖,你會看到每一個區塊的區塊頭裡,除了要標示該區塊的 Merkle Root 值以外,還需要標示前一個區塊的 hash 值,這樣區塊之間才知道彼此的順序。
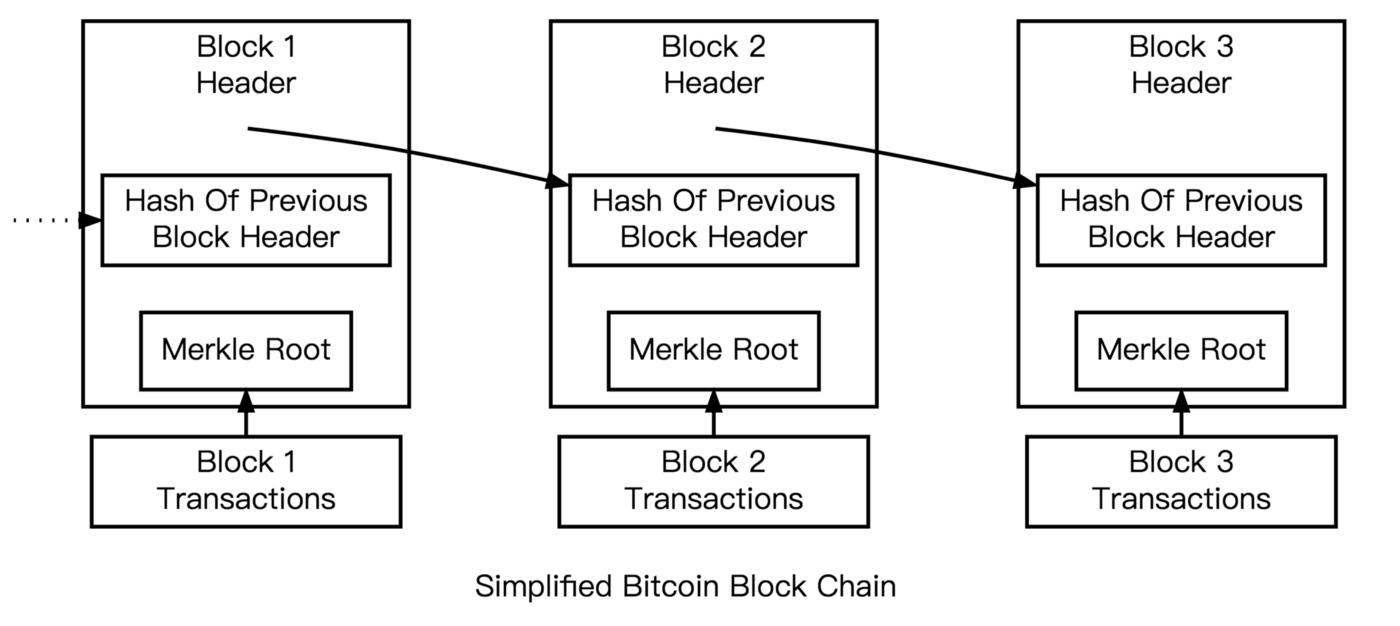
所以具體的區塊生成方式會是:礦工驗證完當前區塊的所有交易有效性後,會接著算出這些交易的 Merkle Root 值。接著礦工會把這些交易紀錄封裝起來,然後在區塊頭上附上幾個資訊:前一個區塊的 hash 值、當前區塊的 Merkle Root 值,這兩個值的大小都是 32 Bytes。
除了這兩個主要資訊外,區塊頭還會有當前區塊的版本號 version(4 Bytes)、當前區塊的生成時間 time(4 Bytes)、成為此區塊的礦工的難度 target_bits(4 Bytes)、隨機數 nounce(4 Bytes)等資訊,這些參數的功用會在後面解釋。

總體而言,任何區塊頭的大小都是 80 Bytes。把區塊頭綁在它對應的那一批交易紀錄上,一個完整的區塊就誕生了。而若把一個區塊頭取 hash,就會得到這個區塊的 hash 值,供下一個區塊的區塊頭使用。
讓後一個區塊包含前一個區塊的 hash 值有個好處,就是一但有一個區塊的交易內容被竄改了,它的 hash 值就會改變,而這個改變會一路傳遞到接在它之後的所有區塊,於是大家便能很快地發現這個區塊鏈被竄改過。
PoW,礦工解題大賽
我們現在已經知道區塊是怎麼生成的了,也知道礦工在製造完區塊後,系統會給他一點比特幣當獎勵。但是比特幣的區塊鏈系統裡有幾千萬人,這麼多人裡頭究竟誰才有資格當礦工呢?如果礦工每次都是同一個人當,而這個人在生成區塊的過程中亂來,那該怎麼辦呢?
為了解決這個問題,比特幣的發明者中本聰在他的設計中引入了 PoW(Proof of Work) 共識機制。這個機制的思路是這樣的:既然大家都想當礦工,那就用比賽的吧。系統會出一個難題給大家,誰最先解出這個難題,誰就能當負責打包下一個區塊的礦工。而這個解難題的過程,就叫做「挖礦」。
PoW 共識機制在比特幣的區塊鏈系統中的具體的實作方法如下:
定義參數 version 代表當前區塊的版本號,prev_hash 代表上一個區塊的 hash 值,merkle_root 代表當前區塊要打包的交易的 Merkle Root 值,time 代表當前區塊的生成時間,target_bits 代表這次挖礦的難度,nounce 則是一個隨機數。
礦工們「挖礦」的這個動作,具體行動就是要找到一個 nounce 值,這個 nounce 值必須能讓這個區塊的區塊頭在被 SHA256 函數連續 hash 兩次後,得到的 hash 值滿足下面這條不等式:
SHA256(SHA256(version + prev_hash + merkle_root + time + target_bits + nounce)) < TARGET
在這條不等式裡頭,TARGET 是一個 256 bits 的數字,target_bits 的大小會決定 TARGET 的範圍。舉例來說,如果 target_bits 的值是 17,那麼 TARGET 開頭的前 17 個數字都得是 0。當 target_bits 的值愈大時,TARGET 就愈小,滿足上面那條不等式條件的 nounce 就會愈難找。
我們知道 nounce 值的大小是 4 Bytes,也就是 32 bits。這意味著 nounce 的可能性有 2 的 32 次方種,換算成十進位大約就是 43 億種。由於雜湊函數沒辦法回推,所以要找到滿足這條不等式的 nounce,只能靠電腦暴力搜索,一個一個試,從 0 開始一路試到 43 億,直到找到符合條件的 nounce 為止。最先找到 nounce 值的礦工,就可以打包當前的區塊。
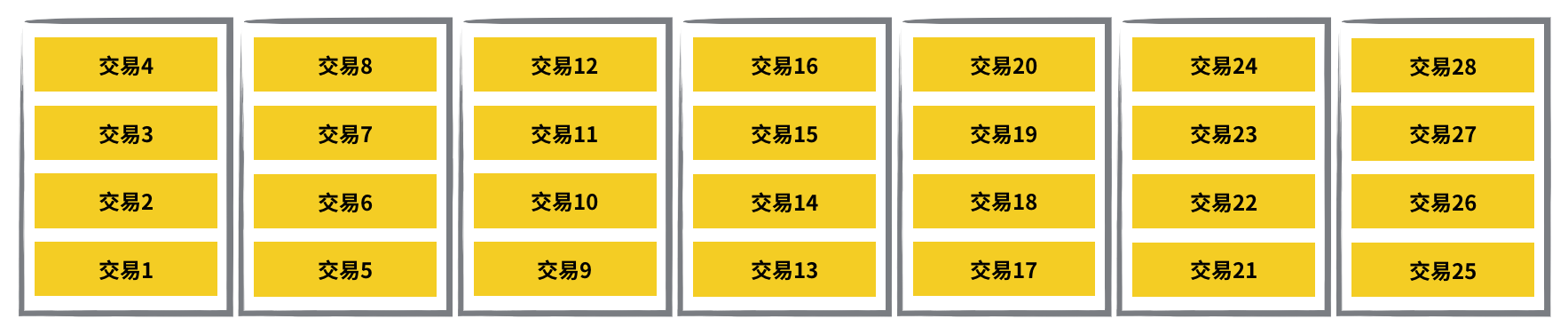
這邊得特別講清楚的一點是,礦工們在打包區塊時,他們決定裝進這個區塊裡的交易不一定會完全相同,這些交易只要滿足 UTXO 的帳本輸入輸出結構,就可以被打包。
以下圖的交易結構為例,假設礦工一號想要把交易 3、4、5、7 打包起來,礦工二號想要把交易 3、4、5、6 打包起來,這兩種打包方式都是合法的。但如果礦工三號想要把交易 3、4、5、8 打包起來,這就不合法,因為交易 8 的輸入來自交易 6 和交易 7,而礦工三號並沒有把這兩個交易選進來。
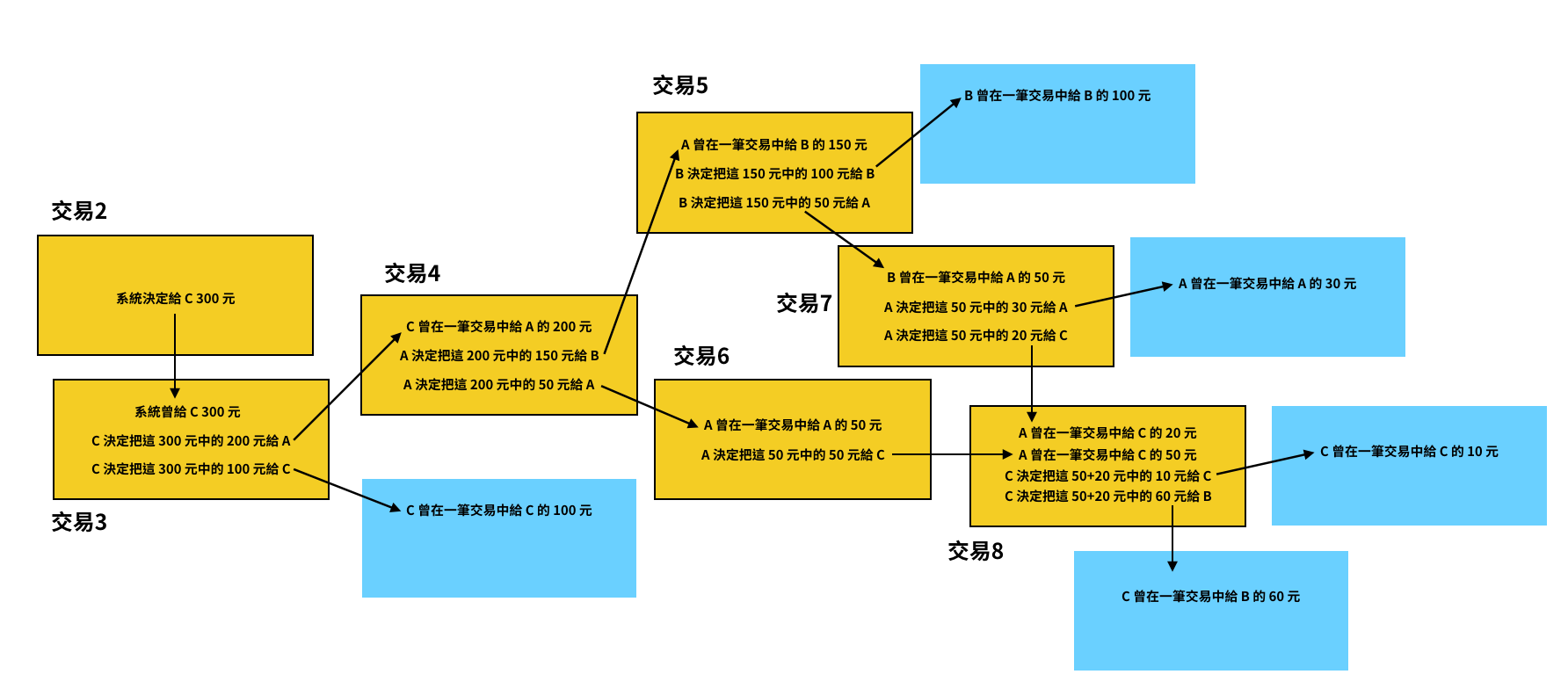
目前我們知道,礦工一號希望把交易 3、4、5、7 做成下一個區塊,礦工二號希望打包交易 3、4、5、6 做成下一個區塊。那究竟要怎麼決定下一個區塊是哪一組呢?答案是看誰先把 nounce 值計算出來。
由於交易 3、4、5、7 的 Merkle Root 值和交易 3、4、5、6 的 Merkle Root 值不一樣,所以礦工一號和礦工二號等於是各自在解各自的難題,他們在找的 nounce 值也不一樣。先把自己題目裡的 nounce 解出來的礦工,就可以把他打包的區塊接入區塊鏈裡頭。
要是兩名礦工同時把 nounce 解出來,那麼他們的區塊就會同時有效,此時區塊鏈就會分叉。在遇到分叉的情況時,其餘的礦工有的會收到礦工一號的那條分支,有的則會收到礦工二號的那條分支。
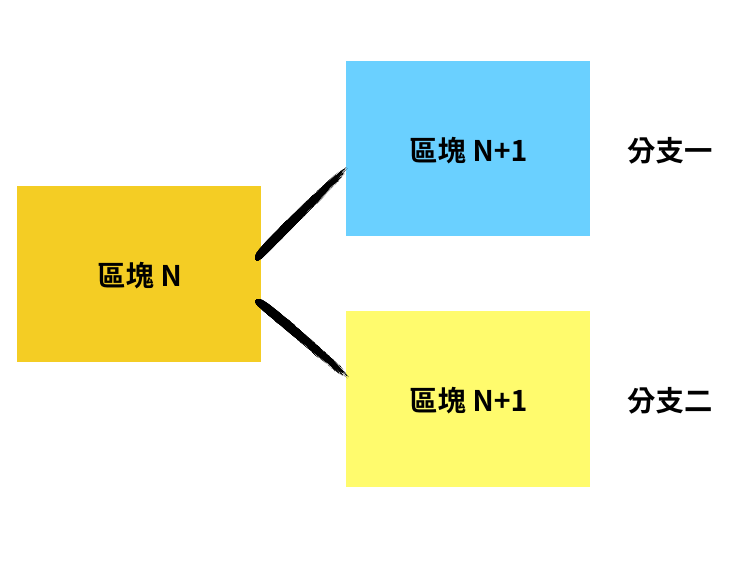
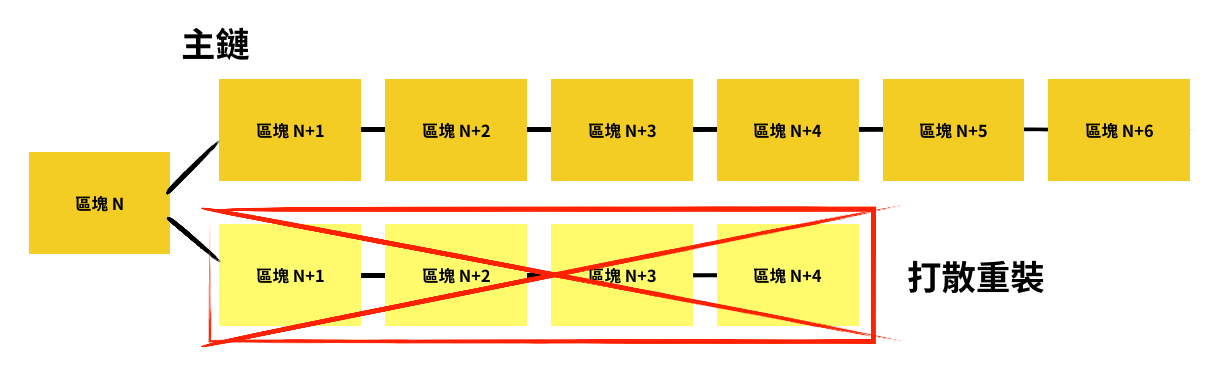
礦工們會在各自的分支裡頭繼續構建下一個區塊。以分叉點為起點,只要其中一條分支率先完成六個區塊,這條分支就會變成「主鏈」,而另一條分支裡頭的交易會被打散,讓礦工們重新打包成新的區塊接在主鏈後面。礦工只有在打包主鏈的區塊時,才能獲得系統給予的比特幣獎勵。
在中本聰原本的設想中,每個帳戶只會有一台電腦,一台電腦也就只有一顆 CPU,所以大家的運算能力是差不多的,因此每個人獲得打包區塊資格的機率是一樣的。如果有人想要保證自己能獲得打包區塊的資格,他就得買幾千台電腦,透過增加自己暴力搜索的「算力」來加大自己先算出 nounce 值的機率。但這樣做所耗費的電力和設備成本是很大的,會抵銷掉打包區塊所獲得的收益。
雙花攻擊
我們知道對任何帳戶之間的交易而言,每一筆交易的輸入,都必須是來自之前某一筆交易的輸出。我們也知道,唯有被裝上區塊鏈的交易,才是被驗證有效的。
在這兩個事實下,有心人士想出了一個從系統設計中牟利的方法,叫做「雙花攻擊」。
在前面在介紹 UTXO 帳本模型時,我們是用 A、B、C 三人接連執行的交易 3~8 來當例子的。現在我們回到這個例子,來看看 A 可以怎麼樣對 C 發起雙花攻擊。
假設交易 3~8 都還沒被礦工打包成區塊,所以此時此刻它們暫時是無效的,要等待礦工們驗證並加入區塊後才會生效。
在交易 6 裡頭,A 為了跟 C 買書,他把在交易 4 中留給自己的 50 元當作交易 6 的輸入,把它們轉給了 C。這時 A 發現交易 6 雖然已經執行了,但還沒被礦工們驗證、打包。
於是 A 對自己開啟了交易 9,並重新把他在交易 4 中留給自己的 50 元當作交易 9 的輸入,把這些錢轉給自己。交易 6 和交易 9 的輸入都來自交易 4 的 50 元,這意味著同一筆錢被花費兩次了,這就叫「雙花」。
當礦工們在打包交易時,系統是不會容許同一條鏈上出現雙花的情況,所以比較晚執行的交易 9 會被取消。但是如果 A 自己跑去當礦工,情況就不ㄧ樣了。
我們在前面介紹分叉時提到,礦工二號希望打包交易 3、4、5、6。如果此時 A 跑去當礦工,希望打包交易 3、4、5、9,然後他和礦工二號同時算出 nounce 值,那麼區塊鏈就會分叉。
A 接著只要再接再厲,想辦法率先讓自己的分支先打包出六個區塊,那麼他的分支就會變成主鏈,交易 9 就會正式獲得驗證。而礦工二號原本打包進區塊的交易 6 則會被重新打散。
當交易 6 想進入主鏈重新驗證時,由於它的輸入金額已經在交易 9 中被花掉了,而交易 9 已經通過主鏈的驗證,系統便會以拒絕雙花為由把交易 6 取消掉。此時 C 雖然已經把書交給 A 了,卻會因為交易被取消而收不到錢,這就叫雙花攻擊。
雖然理論上雙花攻擊可行,但在現實世界裡一個人要成功發起雙花攻擊,成本往往會遠高於收益。原因在於,雙花攻擊的前提是,攻擊者必須要讓「自己雙花的交易所在的分支」成為主鏈,所以他要保證自己能在這條分支上連續打包六個以上的區塊,並且打包的速度要比另一個分支還快。
假設 A 手上握有整個比特村裡 10% 的算力,而比特村的其他人一共擁有 90% 的算力,兩方各在自己的分支上打造區塊、比拼速度。由於 90% 算力遠大於 10% 還大,所以比特村一眾所在的分支要成為主鏈幾乎是勝券在握。但如果 A 掌握了超過 51% 的算力,那 A 就會有很大的機會讓自己的分支變成主鏈了。
但就像前面所提過的,要掌握超過 51% 的算力,需要花費鉅額的成本在用電和購買設備上,收益和成本差距太大,所以雙花攻擊本身在現實世界是不切實際的。
挖礦生態的演化
在比特幣推出的早期,大家都是在各自的電腦中挖礦(也就是計算 nounce 值),每個人的電腦算力都差不多,所以能成為打包區塊的礦工的機率也差不多。
不過人們很快的發現,與其用 CPU 挖礦,GPU 更有效率。你可以把單核 CPU 想像成一個特種兵,多核 CPU 就是一小隻特種部隊。GPU 的核數多達幾千個,每一核都是一個小兵,但是幾千核下來就是一支大軍。
當電腦要執行 nounce 值的暴力搜索時,使用 CPU 是殺雞用牛刀,使用 GPU 的效率往往是 CPU 的好幾百倍。所以很多人開始升級電腦裡的 GPU,大家挖礦的算力也開始有了落差。
隨著人們意識到比特幣的價值不斷飛漲時,愈來愈多人便開始湧入比特幣的圈子裡,成為裡頭的礦工。人們甚至為此設計出專門用來挖礦的礦機,諸如「礦池」的機制也開始出現。
礦池的概念,是讓許多礦工把算力投入到同一個池子裡頭,大家把算力集結起來一起算 nounce 值。一旦成功獲得打包區塊的權利,系統就會給予比特幣獎勵,這些獎勵會再依照大家貢獻的算力比例來分配給所有參與的礦工。
值得一提的是,在比特幣的系統裡,打從一開始就規定了比特幣的總量是 2100 萬個,單位是 btc。在礦工挖礦時,前 21 萬個區塊裡每個區塊的打包獎勵是 50 btc,介於 21 萬和 42 萬之間的區塊裡獎勵是 25 btc,每過 21 萬個區塊,挖礦獎勵就會減半。
由等比數列可以算出,21 萬 × 50 btc × (1+0.5+0.25+……) 得出來的值剛好是 2100 萬 btc,也就是比特幣的總量。而比特幣從 2009 年出現至今,區塊打包獎勵大約每四年減半ㄧ次,當前每個區塊的打包獎勵已經達到 12.5 btc 了。
PoW 的共識機制衍生出區塊鏈的繁榮生態,但這些挖礦的過程卻也導致了大量電力資源的浪費。根據 Bitcoin Energy Consumption Index 統計,比特幣挖礦在 2017 年一共消耗了約 29.51兆瓦小時(TWh)的電量,也就是全球總電力消耗的0.13%。
為了解決能源浪費的問題,其他新興的虛擬貨幣推出了 PoS、DPoS 等新的共識機制,有興趣可以 Google 深入暸解,這裡就不多提了。
比特幣的價值

這篇的最後,我們來談談比特幣作為貨幣的價值是怎麼產生的。在那之前,先來思考一個問題:為什麽貨幣具有價值?
在古代,人們交易的方式是以物易物。假設 A 擁有一籃蘋果,B 擁有兩塊肉,兩人可能會在一番討論後,決定用三顆蘋果換一塊肉。這個交易能完成,是因為 A、B 對雙方擁有的東西做了價值判斷,並在這個判斷上達成共識,所以他們最後一致認同三顆蘋果跟一塊肉的價值差不多。
這種協商以物易物的交易模式有個缺點,就是每次交易都要花一堆時間討論。隨著人們發現這種它的不便以後,「價格」的觀念開始出現了。
一群買家和賣家共同組成了「市場」,每個人都可以給自己在市場中賣的商品一個數字,數字大的價值就高,數字小的價值就低。這個數字就是商品的「價格」。
現在市場中的商品都有價格了。假設 A 說自己的蘋果一顆值 300 元,B 說自己的肉一塊值 100 元,很快地 A 會發現沒有任何人願意拿東西跟他換蘋果。在市場的壓力之下,A 只好慢慢地把價格降低,直到有人願意拿東西跟他換蘋果為止。最後蘋果的穩定價格變成一顆 30 元,這就是這個商品價格在市場中平衡出來的結果。
這裡又衍生出一個問題了:如果有人只想要買一顆蘋果,但是市場中所有東西的價格都比 30 元高,那他要拿什麼東西跟 A 換呢?你會發現,如果市場中每一筆交易都得用以物易物的方式才能完成,交易依然會很沒效率。
為了增加市場的運轉效率,這個市場的人們決定票選出幾個人作為管理者。管理者到處收集了一堆小石頭,並和大家達成共識,規定「每顆石頭代表 1元」。從今以後,人們在買東西時只要拿石頭去買,賣東西時就收取石頭。
由於交易的基本單位變小了,市場的交易因此變得更順暢了。而在這裡,石頭就是這個市場裡通用的貨幣。
既然石頭不能吃、不能穿,為什麼大家還願意使用它來交易呢?這是因為市場與大家達成了「共識」,認定它可以當作交易的單位。這個共識賦予了石頭價值。
現在考慮一個情況:有些人把石頭花光了,沒錢買東西,於是跑到野外去撿了一堆新的石頭,並把這些石頭帶到市場裡買東西。這樣的舉動讓市場中流動的石頭愈來愈多,商家不得不把商品的價格提高,否則商品都會瞬間被拿著一堆石頭的客人一掃而空。這個現象就叫通貨膨脹。
管理者發現這個問題後,經過一番調整,決定把「黃金」訂成新的通用貨幣。石頭到處都可以撿,但是黃金非常稀缺,大家平常不可能憑空生出新的黃金,所以它不容易出現通貨膨脹。不過黃金的稀缺性,卻也造成了一個問題,就是它的數量不夠用來當作貨幣。
於是管理者印製了一些紙鈔,並對市場中的大眾宣稱,只要你拿這些紙鈔過來找管理者,這些紙鈔就可以換取黃金。但是平時在交易時,大家就用紙鈔交易吧。
在這裡,紙鈔就是一個以黃金儲備為擔保的「本位貨幣」。它必須滿足兩個條件:第一,這些紙鈔難以偽造。第二,當你拿著紙鈔前去找管理者時,你可以用它來兌換黃金。
從上述的例子中,你會發現市場裡的貨幣單位和規則不斷地在進化,經過了以物易物、石頭、貴金屬、本位貨幣等不同階段。而在現代,人類使用的貨幣則主要是「信用貨幣」。
信用貨幣跟本位貨幣的共同特徵在於就是它們難以偽造,只有政府有辦法發行。但它們的差異在於,本位貨幣是以貴金屬儲備為擔保,信用貨幣則是以政府的信用為擔保。
什麼是以信用做擔保呢?言下之意就是,政府告訴大家「你們安心使用這些貨幣吧,偽鈔、通貨膨漲等各式各樣的問題,我們政府會嚴格把關,請相信政府的能力」。政府和國內的民眾們達成了這樣的共識以後,政府發行的信用貨幣就變得能在國內通用了。
有了信用貨幣的機制後,政府便可以根據國家當下的經濟狀況,選擇透過加印或收回部分貨幣的方式,把控市場中流動的貨幣量,進而調節經濟的穩定性。當然,如果這個動作沒做好,一不小心加印太多信用貨幣,就有可能造成通貨膨脹。
到目前為止,不論是哪一種貨幣,你會發現它的價值皆取決於使用這些貨幣的人的共識。這意味著,只要有人願意用比特幣買東西、有人願意在賣東西時收取比特幣,比特幣這個貨幣就有了價值。
為什麼大家會願意使用比特幣呢?這邊列舉幾個我認為比較主要的原因:
- 信用貨幣會根據不同的政府機構,受到地理上的限制。你拿一疊台幣到美國,基本上是沒辦法消費的。但是當你使用比特幣時,你可以直接在電子設備上進行端對端支付,世界各地的人都願意接收它。
- 比特幣無法偽造,而且它的數量在系統一開始就設計好了。當全部的比特幣都被挖出來時,貨幣量剛好就是 2100 萬 btc。
- 在區塊鏈技術的支持下,用比特幣進行的交易無法被竄改,沒有任何人或組織有能力操控這個系統。
雖然比特幣已經被愈來愈多人使用,但相較於信用貨幣,它也有自己的侷限。
舉例來說,你在一個炎熱的夏日走進超商想買杯飲料,要價台幣 25 元。你知道不論你是今天買、明天買還是後天買,價格可能稍微有些漲跌,但差不多都是 25 元。在不考慮飲料市場的波動下,你對飲料價格會有這樣的預期,是因為你認為台幣的價值是穩定的,而這個信念源自於你對政府的信心。
如果一個國家的政府很爛,每天加印大把大把的鈔票,導致物價不斷上漲,今天花一千塊可以買到的東西,明天變成要價十萬,那麼貨幣就會變成廢紙,你也會因此對政府失去信心。
由此可見,在信用貨幣背後體現的,其實是一個國家的整體實力。區塊鏈和比特幣的系統雖然有完成交易需要的所有功能,但是它背後沒有任何國家的信用支撐。如果觀察比特幣的幣值在過去十年的波動,你會發現比起貨幣,它更像是一種投資品。
因此,比特幣是否能成為真正意義上的國際通用貨幣,個人認為仍有待時間檢驗。但不可否認的是,它背後的區塊鏈技術的確是近年來最重要的科技突破之一。